Vision-language modeling grounds language understanding in corresponding visual inputs, which can be useful for the development of important products and tools. For example, an image captioning model generates natural language descriptions based on its understanding of a given image. While there are various challenges to such cross-modal work, significant progress has been made in the past few years on vision-language modeling thanks to the adoption of effective vision-language pre-training (VLP). This approach aims to learn a single feature space from both visual and language inputs, rather than learning two separate feature spaces, one each for visual inputs and another for language inputs. For this purpose, existing VLP often leverages an object detector, like Faster R-CNN, trained on labeled object detection datasets to isolate regions-of-interest (ROI), and relies on task-specific approaches (i.e., task-specific loss functions) to learn representations of images and texts jointly. Such approaches require annotated datasets or time to design task-specific approaches, and so, are less scalable.
To address this challenge, in “SimVLM: Simple Visual Language Model Pre-training with Weak Supervision”, we propose a minimalist and effective VLP, named SimVLM, which stands for “Simple Visual Language Model”. SimVLM is trained end-to-end with a unified objective, similar to language modeling, on a vast amount of weakly aligned image-text pairs (i.e., the text paired with an image is not necessarily a precise description of the image). The simplicity of SimVLM enables efficient training on such a scaled dataset, which helps the model to achieve state-of-the-art performance across six vision-language benchmarks. Moreover, SimVLM learns a unified multimodal representation that enables strong zero-shot cross-modality transfer without fine-tuning or with fine-tuning only on text data, including for tasks such as open-ended visual question answering, image captioning and multimodal translation.
Model and Pre-training Procedure
Unlike existing VLP methods that adopt pre-training procedures similar to masked language modeling (like in BERT), SimVLM adopts the sequence-to-sequence framework and is trained with a one prefix language model (PrefixLM) objective, which receives the leading part of a sequence (the prefix) as inputs, then predicts its continuation. For example, given the sequence “A dog is chasing after a yellow ball”, the sequence is randomly truncated to “A dog is chasing” as the prefix, and the model will predict its continuation. The concept of a prefix similarly applies to images, where an image is divided into a number of “patches”, then a subset of those patches are sequentially fed to the model as inputs—this is called an “image patch sequence”. In SimVLM, for multimodal inputs (e.g., images and their captions), the prefix is a concatenation of both the image patch sequence and prefix text sequence, received by the encoder. The decoder then predicts the continuation of the textual sequence. Compared to prior VLP models combining several pre-training losses, the PrefixLM loss is the only training objective and significantly simplifies the training process. This approach for SimVLM maximizes its flexibility and universality in accommodating different task setups.
Finally, due to its success for both language and vision tasks, like BERT and ViT, we adopt the Transformer architecture as the backbone of our model, which, unlike prior ROI-based VLP approaches, enables the model to directly take in raw images as inputs. Moreover, inspired by CoAtNet, we adopt a convolution stage consisting of the first three blocks of ResNet in order to extract contextualized patches, which we find more advantageous than the naïve linear projection in the original ViT model. The overall model architecture is illustrated below.
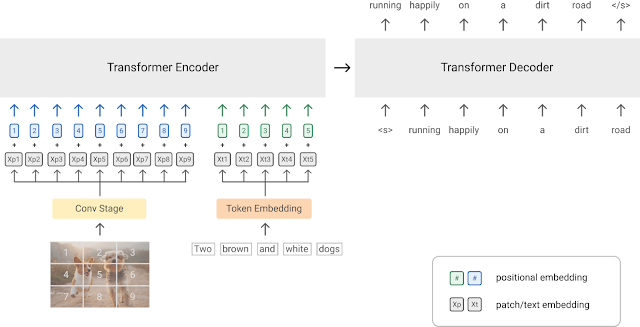 |
| Overview of the SimVLM model architecture. |
The model is pre-trained on large-scale web datasets for both image-text and text-only inputs. For joint vision and language data, we use the training set of ALIGN which contains about 1.8B noisy image-text pairs. For text-only data, we use the Colossal Clean Crawled Corpus (C4) dataset introduced by T5, totaling 800G web-crawled documents.
Benchmark Results
After pre-training, we fine-tune our model on the following multimodal tasks: VQA, NLVR2, SNLI-VE, COCO Caption, NoCaps and Multi30K En-De. For example, for VQA the model takes an image and corresponding questions about the input image, and generates the answer as output. We evaluate SimVLM models of three different sizes (base: 86M parameters, large: 307M and huge: 632M) following the same setup as in ViT. We compare our results with strong existing baselines, including LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNIMO, VinVL, and find that SimVLM achieves state-of-the-art performance across all these tasks despite being much simpler.
| VQA | NLVR2 | SNLI-VE | CoCo Caption | |||||||||||
| Model | test-dev | test-std | dev | test-P | dev | test | B@4 | M | C | S | ||||
| LXMERT | 72.4 | 72.5 | 74.9 | 74.5 | - | - | - | - | - | - | ||||
| VL-T5 | - | 70.3 | 74.6 | 73.6 | - | - | - | - | 116.5 | - | ||||
| UNITER | 73.8 | 74 | 79.1 | 80 | 79.4 | 79.4 | - | - | - | - | ||||
| OSCAR | 73.6 | 73.8 | 79.1 | 80.4 | - | - | 41.7 | 30.6 | 140 | 24.5 | ||||
| Villa | 74.7 | 74.9 | 79.8 | 81.5 | 80.2 | 80 | - | - | - | - | ||||
| SOHO | 73.3 | 73.5 | 76.4 | 77.3 | 85 | 85 | - | - | - | - | ||||
| UNIMO | 75.1 | 75.3 | - | - | 81.1 | 80.6 | 39.6 | - | 127.7 | - | ||||
| VinVL | 76.6 | 76.6 | 82.7 | 84 | - | - | 41 | 31.1 | 140.9 | 25.2 | ||||
| SimVLM base | 77.9 | 78.1 | 81.7 | 81.8 | 84.2 | 84.2 | 39 | 32.9 | 134.8 | 24 | ||||
| SimVLM large | 79.3 | 79.6 | 84.1 | 84.8 | 85.7 | 85.6 | 40.3 | 33.4 | 142.6 | 24.7 | ||||
| SimVLM huge | 80 | 80.3 | 84.5 | 85.2 | 86.2 | 86.3 | 40.6 | 33.7 | 143.3 | 25.4 | ||||
| Evaluation results on a subset of 6 vision-language benchmarks in comparison with existing baseline models. Metrics used above (higher is better): BLEU-4 (B@4), METEOR (M), CIDEr (C), SPICE (S). Similarly, evaluation on NoCaps and Multi30k En-De also show state-of-the-art performance. |
Zero-Shot Generalization
Since SimVLM has been trained on large amounts of data from both visual and textual modalities, it is interesting to ask whether it is capable of performing zero-shot cross-modality transfer. We examine the model on multiple tasks for this purpose, including image captioning, multilingual captioning, open-ended VQA and visual text completion. We take the pre-trained SimVLM and directly decode it for multimodal inputs with fine-tuning only on text data or without fine-tuning entirely. Some examples are given in the figure below. It can be seen that the model is able to generate not only high-quality image captions, but also German descriptions, achieving cross-lingual and cross-modality transfer at the same time.
 |
| Examples of SimVLM zero-shot generalization. (a) Zero-shot image captioning: Given an image together with text prompts, the pre-trained model predicts the content of the image without fine-tuning. (b) zero-shot cross-modality transfer on German image captioning: The model generates captions in German even though it has never been fine-tuned on image captioning data in German. (c) Generative VQA: The model is capable of generating answers outside the candidates of the original VQA dataset. (d) Zero-shot visual text completion: The pre-trained model completes a textual description grounded on the image contents; (e) Zero-shot open-ended VQA: The model provides factual answers to the questions about images, after continued pre-training on the WIT dataset. Images are from NoCaps, which come from the Open Images dataset under the CC BY 2.0 license. |
To quantify SimVLM’s zero-shot performance, we take the pre-trained, frozen model and decode it on the COCO Caption and NoCaps benchmarks, then compare with supervised baselines. Even without supervised fine-tuning (in the middle-rows), SimVLM can reach zero-shot captioning quality close to the quality of supervised methods.
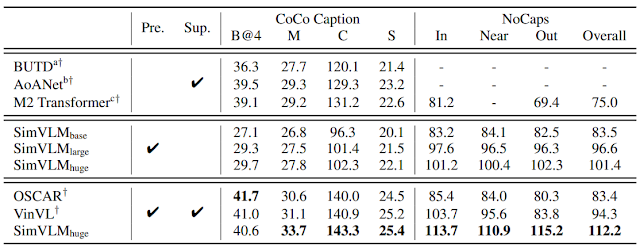 |
| Zero shot image captioning results. Here “Pre.” indicates the model is pre-trained and “Sup.” means the model is finetuned on task-specific supervision. For NoCaps, [In, Near, Out] refer to in-domain, near-domain and out-of-domain respectively. We compare results from BUTD, AoANet, M2 Transformer, OSCAR and VinVL. Metrics used above (higher is better): BLEU-4 (B@4), METEOR (M), CIDEr (C), SPICE (S). For NoCaps, CIDEr numbers are reported. |
Conclusion
We propose a simple yet effective framework for VLP. Unlike prior work using object detection models and task-specific auxiliary losses, our model is trained end-to-end with a single prefix language model objective. On various vision-language benchmarks, this approach not only obtains state-of-the-art performance, but also exhibits intriguing zero-shot behaviors in multimodal understanding tasks.
Acknowledgements
We would like to thank Jiahui Yu, Adams Yu, Zihang Dai, Yulia Tsvetkov for preparation of the SimVLM paper, Hieu Pham, Chao Jia, Andrew Dai, Bowen Zhang, Zhifeng Chen, Ruoming Pang, Douglas Eck, Claire Cui and Yonghui Wu for helpful discussions, Krishna Srinivasan, Samira Daruki, Nan Du and Aashi Jain for help with data preparation, Jonathan Shen, Colin Raffel and Sharan Narang for assistance on experimental settings, and others on the Brain team for support throughout this project.

Machine learning (ML) is increasingly being used in real-world applications, so understanding the uncertainty and robustness of a model is necessary to ensure performance in practice. For example, how do models behave when deployed on data that differs from the data on which they were trained? How do models signal when they are likely to make a mistake?
To get a handle on an ML model's behavior, its performance is often measured against a baseline for the task of interest. With each baseline, researchers must try to reproduce results only using descriptions from the corresponding papers , which results in serious challenges for replication. Having access to the code for experiments may be more useful, assuming it is well-documented and maintained. But even this is not enough, because the baselines must be rigorously validated. For example, in retrospective analyses over a collection of works [1, 2, 3], authors often find that a simple well-tuned baseline outperforms more sophisticated methods. In order to truly understand how models perform relative to each other, and enable researchers to measure whether new ideas in fact yield meaningful progress, models of interest must be compared to a common baseline.
In “Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning”, we introduce Uncertainty Baselines, a collection of high-quality implementations of standard and state-of-the-art deep learning methods for a variety of tasks, with the goal of making research on uncertainty and robustness more reproducible. The collection spans 19 methods across nine tasks, each with at least five metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components and with minimal dependencies outside of the framework in which it is written. The included pipelines are implemented in TensorFlow, PyTorch, and Jax. Additionally, the hyperparameters for each baseline have been extensively tuned over numerous iterations so as to provide even stronger results.
Uncertainty Baselines
As of this writing, Uncertainty Baselines provides a total of 83 baselines, comprising 19 methods encompassing standard and more recent strategies over nine datasets. Example methods include BatchEnsemble, Deep Ensembles, Rank-1 Bayesian Neural Nets, Monte Carlo Dropout, and Spectral-normalized Neural Gaussian Processes. It acts as a successor in merging several popular benchmarks in the community: Can You Trust Your Model's Uncertainty?, BDL benchmarks, and Edward2's baselines.
| Dataset | Inputs | Output | Train Examples | Test Datasets |
| CIFAR | RGB images | 10-class distribution | 50,000 | 3 |
| ImageNet | RGB images | 1000-class distribution | 1,281,167 | 6 |
| CLINC Intent Detection | Dialog system query text | 150-class distribution (in 10 domains) | 15,000 | 2 |
| Kaggle's Diabetic Retinopathy Detection | RGB images | Probability of Diabetic Retinopathy | 35,126 | 1 |
| Wikipedia Toxicity | Wikipedia comment text | Probability of toxicity | 159,571 | 3 |
A subset of 5 out of 9 available datasets for which baselines are provided. The datasets span tabular, text, and image modalities.
Uncertainty Baselines sets up each baseline under a choice of base model, training dataset, and a suite of evaluation metrics. Each is then tuned over its hyperparameters to maximize performance on such metrics. The available baselines vary among these three axes:
- Base models (architectures) include Wide ResNet 28-10, ResNet-50, BERT, and simple fully-connected networks.
- Training datasets include standard machine learning datasets (CIFAR, ImageNet, and UCI) as well as more real-world problems (Clinc Intent Detection, Kaggle’s Diabetic Retinopathy Detection, and Wikipedia Toxicity).
- Evaluation includes predictive metrics (e.g., accuracy), uncertainty metrics (e.g., selective prediction and calibration error), compute metrics (inference latency), and performance on in- and out-of-distribution datasets.
Modularity and Reusability
In order for researchers to use and build on the baselines, we deliberately optimized them to be as modular and minimal as possible. As seen in the workflow figure below, Uncertainty Baselines introduces no new class abstractions, instead reusing classes that pre-exist in the ecosystem (e.g., TensorFlow’s tf.data.Dataset). The train/evaluation pipeline for each of the baselines is contained in a standalone Python file for that experiment, which can run on CPU, GPU, or Google Cloud TPUs. Because of this independence between baselines, we are able to develop baselines in any of TensorFlow, PyTorch or JAX.
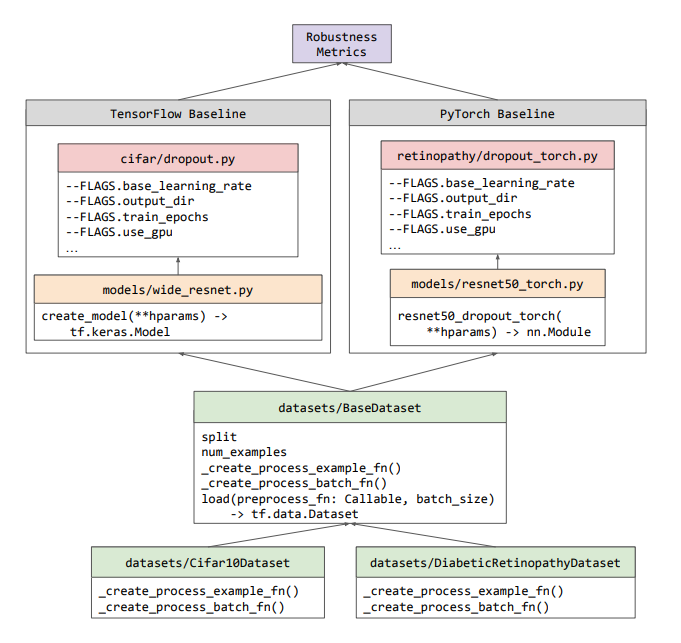 |
| Workflow diagram for how the different components of Uncertainty Baselines are structured. All datasets are subclasses of the BaseDataset class, which provides a simple API for use in baselines written with any of the supported frameworks. The outputs from any of the baselines can then be analyzed with the Robustness Metrics library. |
One area of debate among research engineers is how to manage hyperparameters and other experiment configuration values, which can easily number in the dozens. Instead of using one of the many frameworks built for this, and risk users having to learn yet another library, we opted to simply use Python flags, i.e., flags defined using Abseil that follow Python conventions. This should be a familiar technique to most researchers, and is easy to extend and plug into other pipelines.
Reproducibility
In addition to being able to run each of our baselines using the documented commands and get the same reported results, we also aim to release hyperparameter tuning results and final model checkpoints for further reproducibility. Right now we only have these fully open-sourced for the Diabetic Retinopathy baselines, but we will continue to upload more results as we run them. Additionally, we have examples of baselines that are exactly reproducible up to hardware determinism.
Practical Impact
Each of the baselines included in our repository has gone through extensive hyperparameter tuning, and we hope that researchers can readily reuse this effort without the need for expensive retraining or retuning. Additionally, we hope to avoid minor differences in the pipeline implementations affecting baseline comparisons.
Uncertainty Baselines has already been used in numerous research projects. If you are a researcher with other methods or datasets you would like to contribute, please open a GitHub issue to start a discussion!
Acknowledgements
We would like to thank a number of folks who are codevelopers, provided guidance, and/or helped review this post: Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal.
Over the past 20 months, the COVID-19 pandemic has had a profound impact on daily life, presented logistical challenges for businesses planning for supply and demand, and created difficulties for governments and organizations working to support communities with timely public health responses. While there have been well-studied epidemiology models that can help predict COVID-19 cases and deaths to help with these challenges, this pandemic has generated an unprecedented amount of real-time publicly-available data, which makes it possible to use more advanced machine learning techniques in order to improve results.
In "A prospective evaluation of AI-augmented epidemiology to forecast COVID-19 in the USA and Japan", accepted to npj Digital Medicine, we continued our previous work [1, 2, 3, 4] and proposed a framework designed to simulate the effect of certain policy changes on COVID-19 deaths and cases, such as school closings or a state-of-emergency at a US-state, US-county, and Japan-prefecture level, using only publicly-available data. We conducted a 2-month prospective assessment of our public forecasts, during which our US model tied or outperformed all other 33 models on COVID19 Forecast Hub. We also released a fairness analysis of the performance on protected sub-groups in the US and Japan. Like other Google initiatives to help with COVID-19 [1, 2, 3], we are releasing daily forecasts based on this work to the public for free, on the web [us, ja] and through BigQuery.
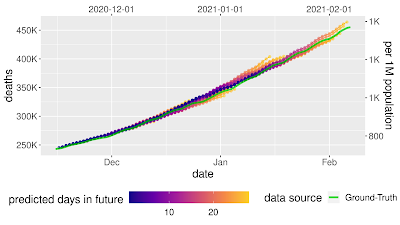 |
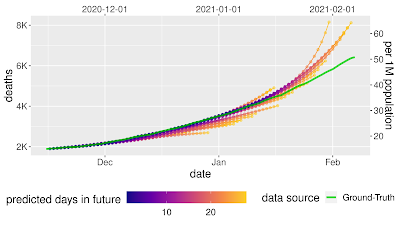 |
| Prospective forecasts for the USA and Japan models. Ground truth cumulative deaths counts (green lines) are shown alongside the forecasts for each day. Each daily forecast contains a predicted increase in deaths for each day during the prediction window of 4 weeks (shown as colored dots, where shading shifting to yellow indicates days further from the date of prediction in the forecasting horizon, up to 4 weeks). Predictions of deaths are shown for the USA (above) and Japan (below). |
The Model
Models for infectious diseases have been studied by epidemiologists for decades. Compartmental models are the most common, as they are simple, interpretable, and can fit different disease phases effectively. In compartmental models, individuals are separated into mutually exclusive groups, or compartments, based on their disease status (such as susceptible, exposed, or recovered), and the rates of change between these compartments are modeled to fit the past data. A population is assigned to compartments representing disease states, with people flowing between states as their disease status changes.
In this work, we propose a few extensions to the Susceptible-Exposed-Infectious-Removed (SEIR) type compartmental model. For example, susceptible people becoming exposed causes the susceptible compartment to decrease and the exposed compartment to increase, with a rate that depends on disease spreading characteristics. Observed data for COVID-19 associated outcomes, such as confirmed cases, hospitalizations and deaths, are used for training of compartmental models.
 |
| Visual explanation of "compartmental” models in epidemiology. People "flow" between compartments. Real-world events, like policy changes and more ICU beds, change the rate of flow between compartments. |
Our framework proposes a number of novel technical innovations:
- Learned transition rates: Instead of using static rates for transitions between compartments across all locations and times, we use machine-learned rates to map them. This allows us to take advantage of the vast amount of available data with informative signals, such as Google's COVID-19 Community Mobility Reports, healthcare supply, demographics, and econometrics features.
- Explainability: Our framework provides explainability for decision makers, offering insights on disease propagation trends via its compartmental structure, and suggesting which factors may be most important for driving compartmental transitions.
- Expanded compartments: We add hospitalization, ICU, ventilator, and vaccine compartments and demonstrate efficient training despite data sparsity.
- Information sharing across locations: As opposed to fitting to an individual location, we have a single model for all locations in a country (e.g., >3000 US counties) with distinct dynamics and characteristics, and we show the benefit of transferring information across locations.
- Seq2seq modeling: We use a sequence-to-sequence model with a novel partial teacher forcing approach that minimizes amplified growth of errors into the future.
Forecast Accuracy
Each day, we train models to predict COVID-19 associated outcomes (primarily deaths and cases) 28 days into the future. We report the mean absolute percentage error (MAPE) for both a country-wide score and a location-level score, with both cumulative values and weekly incremental values for COVID-19 associated outcomes.
We compare our framework with alternatives for the US from the COVID19 Forecast Hub. In MAPE, our models outperform all other 33 models except one — the ensemble forecast that also includes our model’s predictions, where the difference is not statistically significant.
We also used prediction uncertainty to estimate whether a forecast is likely to be accurate. If we reject forecasts that the model considers uncertain, we can improve the accuracy of the forecasts that we do release. This is possible because our model has well-calibrated uncertainty.
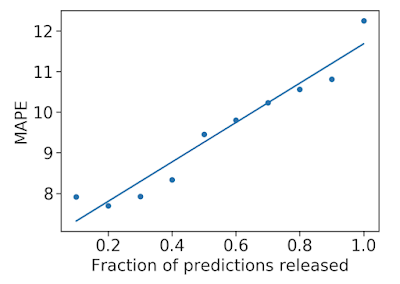 |
| Mean average percentage error (MAPE, the lower the better) decreases as we remove uncertain forecasts, increasing accuracy. |
What-If Tool to Simulate Pandemic Management Policies and Strategies
In addition to understanding the most probable scenario given past data, decision makers are interested in how different decisions could affect future outcomes, for example, understanding the impact of school closures, mobility restrictions and different vaccination strategies. Our framework allows counterfactual analysis by replacing the forecasted values for selected variables with their counterfactual counterparts. The results of our simulations reinforce the risk of prematurely relaxing non-pharmaceutical interventions (NPIs) until the rapid disease spreading is reduced. Similarly, the Japan simulations show that maintaining the State of Emergency while having a high vaccination rate greatly reduces infection rates.
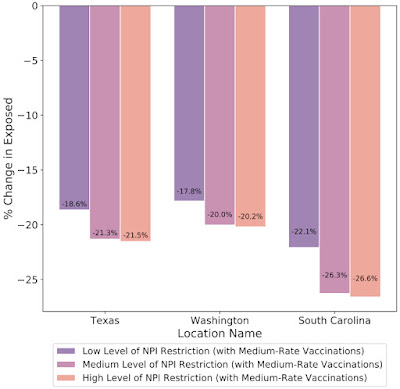 |
| What-if simulations on the percent change of predicted exposed individuals assuming different non-pharmaceutical interventions (NPIs) for the prediction date of March 1, 2021 in Texas, Washington and South Carolina. Increased NPI restrictions are associated with a larger % reduction in the number of exposed people. |
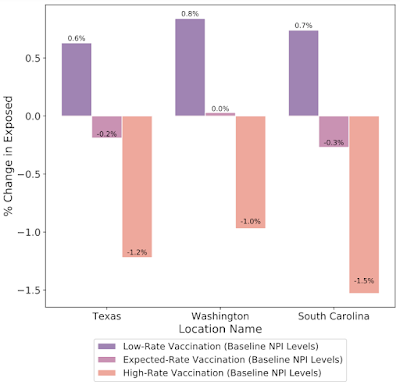 |
| What-if simulations on the percent change of predicted exposed individuals assuming different vaccination rates for the prediction date of March 1, 2021 in Texas, Washington and South Carolina. Increased vaccination rate also plays a key role to reduce exposed count in these cases. |
Fairness Analysis
To ensure that our models do not create or reinforce unfairly biased decision making, in alignment with our AI Principles, we performed a fairness analysis separately for forecasts in the US and Japan by quantifying whether the model's accuracy was worse on protected sub-groups. These categories include age, gender, income, and ethnicity in the US, and age, gender, income, and country of origin in Japan. In all cases, we demonstrated no consistent pattern of errors among these groups once we controlled for the number of COVID-19 deaths and cases that occur in each subgroup.
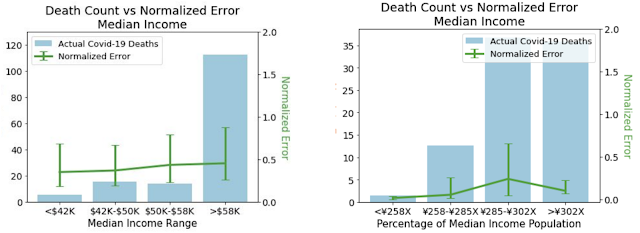 |
| Normalized errors by median income. The comparison between the two shows that patterns of errors don't persist once errors are normalized by cases. Left: Normalized errors by median income for the US. Right: Normalized errors by median income for Japan. |
Real-World Use Cases
In addition to quantitative analyses to measure the performance of our models, we conducted a structured survey in the US and Japan to understand how organisations were using our model forecasts. In total, seven organisations responded with the following results on the applicability of the model.
- Organization type: Academia (3), Government (2), Private industry (2)
- Main user job role: Analyst/Scientist (3), Healthcare professional (1), Statistician (2), Managerial (1)
- Location: USA (4), Japan (3)
- Predictions used: Confirmed cases (7), Death (4), Hospitalizations (4), ICU (3), Ventilator (2), Infected (2)
- Model use case: Resource allocation (2), Business planning (2), scenario planning (1), General understanding of COVID spread (1), Confirm existing forecasts (1)
- Frequency of use: Daily (1), Weekly (1), Monthly (1)
- Was the model helpful?: Yes (7)
To share a few examples, in the US, the Harvard Global Health Institute and Brown School of Public Health used the forecasts to help create COVID-19 testing targets that were used by the media to help inform the public. The US Department of Defense used the forecasts to help determine where to allocate resources, and to help take specific events into account. In Japan, the model was used to make business decisions. One large, multi-prefecture company with stores in more than 20 prefectures used the forecasts to better plan their sales forecasting, and to adjust store hours.
Limitations and next steps
Our approach has a few limitations. First, it is limited by available data, and we are only able to release daily forecasts as long as there is reliable, high-quality public data. For instance, public transportation usage could be very useful but that information is not publicly available. Second, there are limitations due to the model capacity of compartmental models as they cannot model very complex dynamics of Covid-19 disease propagation. Third, the distribution of case counts and deaths are very different between the US and Japan. For example, most of Japan's COVID-19 cases and deaths have been concentrated in a few of its 47 prefectures, with the others experiencing low values. This means that our per-prefecture models, which are trained to perform well across all Japanese prefectures, often have to strike a delicate balance between avoiding overfitting to noise while getting supervision from these relatively COVID-19-free prefectures.
We have updated our models to take into account large changes in disease dynamics, such as the increasing number of vaccinations. We are also expanding to new engagements with city governments, hospitals, and private organizations. We hope that our public releases continue to help public and policy-makers address the challenges of the ongoing pandemic, and we hope that our method will be useful to epidemiologists and public health officials in this and future health crises.
Acknowledgements
This paper was the result of hard work from a variety of teams within Google and collaborators around the globe. We'd especially like to thank our paper co-authors from the School of Medicine at Keio University, Graduate School of Public Health at St Luke’s International University, and Graduate School of Medicine at The University of Tokyo.
In recent years, there has been increasing interest in applying deep learning to medical imaging tasks, with exciting progress in various applications like radiology, pathology and dermatology. Despite the interest, it remains challenging to develop medical imaging models, because high-quality labeled data is often scarce due to the time-consuming effort needed to annotate medical images. Given this, transfer learning is a popular paradigm for building medical imaging models. With this approach, a model is first pre-trained using supervised learning on a large labeled dataset (like ImageNet) and then the learned generic representation is fine-tuned on in-domain medical data.
Other more recent approaches that have proven successful in natural image recognition tasks, especially when labeled examples are scarce, use self-supervised contrastive pre-training, followed by supervised fine-tuning (e.g., SimCLR and MoCo). In pre-training with contrastive learning, generic representations are learned by simultaneously maximizing agreement between differently transformed views of the same image and minimizing agreement between transformed views of different images. Despite their successes, these contrastive learning methods have received limited attention in medical image analysis and their efficacy is yet to be explored.
In “Big Self-Supervised Models Advance Medical Image Classification”, to appear at the International Conference on Computer Vision (ICCV 2021), we study the effectiveness of self-supervised contrastive learning as a pre-training strategy within the domain of medical image classification. We also propose Multi-Instance Contrastive Learning (MICLe), a novel approach that generalizes contrastive learning to leverage special characteristics of medical image datasets. We conduct experiments on two distinct medical image classification tasks: dermatology condition classification from digital camera images (27 categories) and multilabel chest X-ray classification (5 categories). We observe that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images, significantly improves the accuracy of medical image classifiers. Specifically, we demonstrate that self-supervised pre-training outperforms supervised pre-training, even when the full ImageNet dataset (14M images and 21.8K classes) is used for supervised pre-training.
SimCLR and Multi Instance Contrastive Learning (MICLe)
Our approach consists of three steps: (1) self-supervised pre-training on unlabeled natural images (using SimCLR); (2) further self-supervised pre-training using unlabeled medical data (using either SimCLR or MICLe); followed by (3) task-specific supervised fine-tuning using labeled medical data.
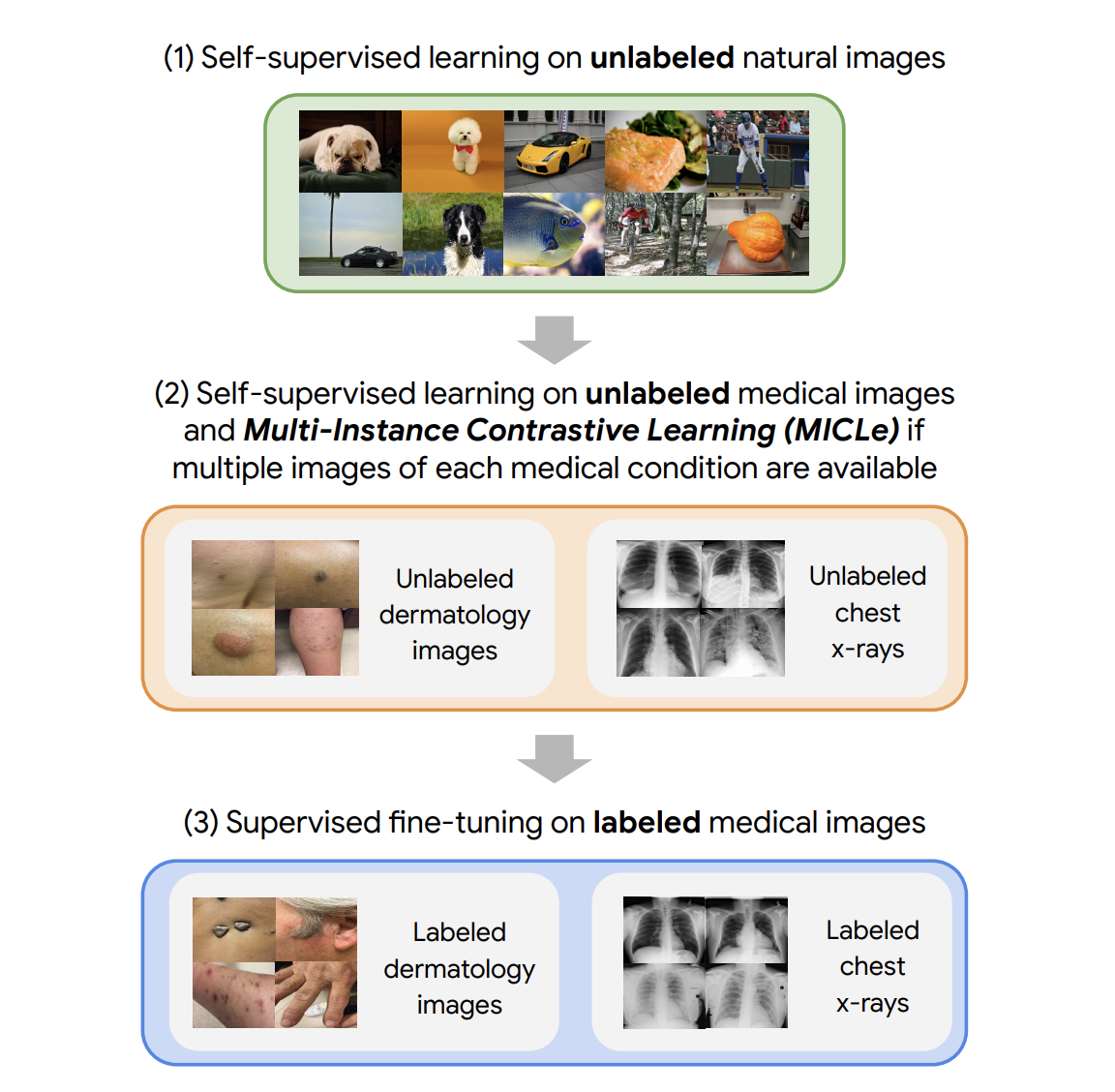 |
| Our approach comprises three steps: (1) Self-supervised pre-training on unlabeled ImageNet using SimCLR (2) Additional self-supervised pre-training using unlabeled medical images. If multiple images of each medical condition are available, a novel Multi-Instance Contrastive Learning (MICLe) strategy is used to construct more informative positive pairs based on different images. (3) Supervised fine-tuning on labeled medical images. Note that unlike step (1), steps (2) and (3) are task and dataset specific. |
After the initial pre-training with SimCLR on unlabeled natural images is complete, we train the model to capture the special characteristics of medical image datasets. This, too, can be done with SimCLR, but this method constructs positive pairs only through augmentation and does not readily leverage patients' meta data for positive pair construction. Alternatively, we use MICLe, which uses multiple images of the underlying pathology for each patient case, when available, to construct more informative positive pairs for self-supervised learning. Such multi-instance data is often available in medical imaging datasets — e.g., frontal and lateral views of mammograms, retinal fundus images from each eye, etc.
Given multiple images of a given patient case, MICLe constructs a positive pair for self-supervised contrastive learning by drawing two crops from two distinct images from the same patient case. Such images may be taken from different viewing angles and show different body parts with the same underlying pathology. This presents a great opportunity for self-supervised learning algorithms to learn representations that are robust to changes of viewpoint, imaging conditions, and other confounding factors in a direct way. MICLe does not require class label information and only relies on different images of an underlying pathology, the type of which may be unknown.
 |
| MICLe generalizes contrastive learning to leverage special characteristics of medical image datasets (patient metadata) to create realistic augmentations, yielding further performance boost of image classifiers. |
Combining these self-supervised learning strategies, we show that even in a highly competitive production setting we can achieve a sizable gain of 6.7% in top-1 accuracy on dermatology skin condition classification and an improvement of 1.1% in mean AUC on chest X-ray classification, outperforming strong supervised baselines pre-trained on ImageNet (the prevailing protocol for training medical image analysis models). In addition, we show that self-supervised models are robust to distribution shift and can learn efficiently with only a small number of labeled medical images.
Comparison of Supervised and Self-Supervised Pre-training
Despite its simplicity, we observe that pre-training with MICLe consistently improves the performance of dermatology classification over the original method of pre-training with SimCLR under different pre-training dataset and base network architecture choices. Using MICLe for pre-training, translates to (1.18 ± 0.09)% increase in top-1 accuracy for dermatology classification over using SimCLR. The results demonstrate the benefit accrued from utilizing additional metadata or domain knowledge to construct more semantically meaningful augmentations for contrastive pre-training. In addition, our results suggest that wider and deeper models yield greater performance gains, with ResNet-152 (2x width) models often outperforming ResNet-50 (1x width) models or smaller counterparts.
 |
| Comparison of supervised and self-supervised pre-training, followed by supervised fine-tuning using two architectures on dermatology and chest X-ray classification. Self-supervised learning utilizes unlabeled domain-specific medical images and significantly outperforms supervised ImageNet pre-training. |
Improved Generalization with Self-Supervised Models
For each task we perform pretraining and fine-tuning using the in-domain unlabeled and labeled data respectively. We also use another dataset obtained in a different clinical setting as a shifted dataset to further evaluate the robustness of our method to out-of-domain data. For the chest X-ray task, we note that self-supervised pre-training with either ImageNet or CheXpert data improves generalization, but stacking them both yields further gains. As expected, we also note that when only using ImageNet for self-supervised pre-training, the model performs worse compared to using only in-domain data for pre-training.
To test the performance under distribution shift, for each task, we held out additional labeled datasets for testing that were collected under different clinical settings. We find that the performance improvement in the distribution-shifted dataset (ChestX-ray14) by using self-supervised pre-training (both using ImageNet and CheXpert data) is more pronounced than the original improvement on the CheXpert dataset. This is a valuable finding, as generalization under distribution shift is of paramount importance to clinical applications. On the dermatology task, we observe similar trends for a separate shifted dataset that was collected in skin cancer clinics and had a higher prevalence of malignant conditions. This demonstrates that the robustness of the self-supervised representations to distribution shifts is consistent across tasks.
 |
| Evaluation of models on distribution-shifted datasets for the chest-xray interpretation task. We use the model trained on in-domain data to make predictions on an additional shifted dataset without any further fine-tuning (zero-shot transfer learning). We observe that self-supervised pre-training leads to better representations that are more robust to distribution shifts. |
 |
| Evaluation of models on distribution-shifted datasets for the dermatology task. Our results generally suggest that self-supervised pre-trained models can generalize better to distribution shifts with MICLe pre-training leading to the most gains. |
Improved Label Efficiency
We further investigate the label-efficiency of the self-supervised models for medical image classification by fine-tuning the models on different fractions of labeled training data. We use label fractions ranging from 10% to 90% for both Derm and CheXpert training datasets and examine how the performance varies using the different available label fractions for the dermatology task. First, we observe that pre-training using self-supervised models can compensate for low label efficiency for medical image classification, and across the sampled label fractions, self-supervised models consistently outperform the supervised baseline. These results also suggest that MICLe yields proportionally higher gains when fine-tuning with fewer labeled examples. In fact, MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x) and 30% of the training data for ResNet152 (2x).
 |
| Top-1 accuracy for dermatology condition classification for MICLe, SimCLR, and supervised models under different unlabeled pre-training datasets and varied sizes of label fractions. MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x). |
Conclusion
Supervised pre-training on natural image datasets is commonly used to improve medical image classification. We investigate an alternative strategy based on self-supervised pre-training on unlabeled natural and medical images and find that it can significantly improve upon supervised pre-training, the standard paradigm for training medical image analysis models. This approach can lead to models that are more accurate and label efficient and are robust to distribution shifts. In addition, our proposed Multi-Instance Contrastive Learning method (MICLe) enables the use of additional metadata to create realistic augmentations, yielding further performance boost of image classifiers.
Self-supervised pre-training is much more scalable than supervised pre-training because class label annotation is not required. We hope this paper will help popularize the use of self-supervised approaches in medical image analysis yielding label efficient and robust models suited for clinical deployment at scale in the real world.
Acknowledgements
This work involved collaborative efforts from a multidisciplinary team of researchers, software engineers, clinicians, and cross-functional contributors across Google Health and Google Brain. We thank our co-authors: Basil Mustafa, Fiona Ryan, Zach Beaver, Jan Freyberg, Jon Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, and Mohammad Norouzi. We also thank Yuan Liu from Google Health for valuable feedback and our partners for access to the datasets used in the research.
The International Conference on Computer Vision 2021 (ICCV 2021), one of the world's premier conferences on computer vision, starts this week. A Champion Sponsor and leader in computer vision research, Google will have a strong presence at ICCV 2021 with more than 50 research presentations and involvement in the organization of a number of workshops and tutorials.
If you are attending ICCV this year, we hope you’ll check out the work of our researchers who are actively pursuing the latest innovations in computer vision. Learn more about our research being presented in the list below (Google affilitation in bold).
Organizing Committee
Diversity and Inclusion Chair: Negar Rostamzadeh
Area Chairs: Andrea Tagliasacchi, Boqing Gong, Ce Liu, Dilip Krishnan, Jordi Pont-Tuset, Michael Rubinstein, Michael S. Ryoo, Negar Rostamzadeh, Noah Snavely, Rodrigo Benenson, Tsung-Yi Lin, Vittorio Ferrari
Publications
MosaicOS: A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Cheng Zhang, Tai-Yu Pan, Yandong Li, Hexiang Hu, Dong Xuan, Soravit Changpinyo, Boqing Gong, Wei-Lun Chao
Learning to Resize Images for Computer Vision Tasks
Hossein Talebi, Peyman Milanfar
Joint Representation Learning and Novel Category Discovery on Single- and Multi-Modal Data
Xuhui Jia, Kai Han, Yukun Zhu, Bradley Green
Explaining in Style: Training a GAN to Explain a Classifier in StyleSpace
Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald, Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani, Inbar Mosseri
Learning Fast Sample Re-weighting without Reward Data
Zizhao Zhang, Tomas Pfister
Contrastive Multimodal Fusion with TupleInfoNCE
Yunze Liu, Qingnan Fan, Shanghang Zhang, Hao Dong, Thomas Funkhouser, Li Yi
Learning Temporal Dynamics from Cycles in Narrated Video
Dave Epstein*, Jiajun Wu, Cordelia Schmid, Chen Sun
Patch Craft: Video Denoising by Deep Modeling and Patch Matching
Gregory Vaksman, Michael Elad, Peyman Milanfar
How to Train Neural Networks for Flare Removal
Yicheng Wu*, Qiurui He, Tianfan Xue, Rahul Garg, Jiawen Chen, Ashok Veeraraghavan, Jonathan T. Barron
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Abdullah Abuolaim*, Mauricio Delbracio, Damien Kelly, Michael S. Brown, Peyman Milanfar
Hybrid Neural Fusion for Full-Frame Video Stabilization
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang
A Dark Flash Normal Camera
Zhihao Xia*, Jason Lawrence, Supreeth Achar
Efficient Large Scale Inlier Voting for Geometric Vision Problems
Dror Aiger, Simon Lynen, Jan Hosang, Bernhard Zeisl
Big Self-Supervised Models Advance Medical Image Classification
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan*, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, Mohammad Norouzi
Physics-Enhanced Machine Learning for Virtual Fluorescence Microscopy
Colin L. Cooke, Fanjie Kong, Amey Chaware, Kevin C. Zhou, Kanghyun Kim, Rong Xu, D. Michael Ando, Samuel J. Yang, Pavan Chandra Konda, Roarke Horstmeyer
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Min Jin Chong, Wen-Sheng Chu, Abhishek Kumar, David Forsyth
Deep Survival Analysis with Longitudinal X-Rays for COVID-19
Michelle Shu, Richard Strong Bowen, Charles Herrmann, Gengmo Qi, Michele Santacatterina, Ramin Zabih
MUSIQ: Multi-Scale Image Quality Transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, Feng Yang
imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose
Thiemo Alldieck, Hongyi Xu, Cristian Sminchisescu
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Xingkui Wei, Zhengqing Chen, Yanwei Fu, Zhaopeng Cui, Yinda Zhang
Differentiable Surface Rendering via Non-Differentiable Sampling
Forrester Cole, Kyle Genova, Avneesh Sud, Daniel Vlasic, Zhoutong Zhang
A Lazy Approach to Long-Horizon Gradient-Based Meta-Learning
Muhammad Abdullah Jamal, Liqiang Wang, Boqing Gong
ViViT: A Video Vision Transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid
The Surprising Impact of Mask-Head Architecture on Novel Class Segmentation (see the blog post)
Vighnesh Birodkar, Zhichao Lu, Siyang Li, Vivek Rathod, Jonathan Huang
Generalize Then Adapt: Source-Free Domain Adaptive Semantic Segmentation
Jogendra Nath Kundu, Akshay Kulkarni, Amit Singh, Varun Jampani, R. Venkatesh Babu
Unified Graph Structured Models for Video Understanding
Anurag Arnab, Chen Sun, Cordelia Schmid
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, Justin Gilmer
Learning Rare Category Classifiers on a Tight Labeling Budget
Ravi Teja Mullapudi, Fait Poms, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Composable Augmentation Encoding for Video Representation Learning
Chen Sun, Arsha Nagrani, Yonglong Tian, Cordelia Schmid
Multi-Task Self-Training for Learning General Representations
Golnaz Ghiasi, Barret Zoph, Ekin D. Cubuk, Quoc V. Le, Tsung-Yi Lin
With a Little Help From My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, Andrew Zisserman
Understanding Robustness of Transformers for Image Classification
Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, Andreas Veit
Impact of Aliasing on Generalization in Deep Convolutional Networks
Cristina Vasconcelos, Hugo Larochelle, Vincent Dumoulin, Rob Romijnders, Nicolas Le Roux, Ross Goroshin
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Tyler R. Scott*, Andrew C. Gallagher, Michael C. Mozer
Contrastive Learning for Label Efficient Semantic Segmentation
Xiangyun Zhao*, Raviteja Vemulapalli, Philip Andrew Mansfield, Boqing Gong, Bradley Green, Lior Shapira, Ying Wu
Interacting Two-Hand 3D Pose and Shape Reconstruction from Single Color Image
Baowen Zhang, Yangang Wang, Xiaoming Deng, Yinda Zhang, Ping Tan, Cuixia Ma, Hongan Wang
Telling the What While Pointing to the Where: Multimodal Queries for Image Retrieval
Soravit Changpinyo, Jordi Pont-Tuset, Vittorio Ferrari, Radu Soricut
SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
Yan Di, Fabian Manhardt, Gu Wang, Xiangyang Ji, Nassir Navab, Federico Tombari
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, Angela Dai
NeRD: Neural Reflectance Decomposition From Image Collections
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, Hendrik P.A. Lensch
THUNDR: Transformer-Based 3D Human Reconstruction with Markers
Mihai Zanfir, Andrei Zanfir, Eduard Gabriel Bazavan, William T. Freeman, Rahul Sukthankar, Cristian Sminchisescu
Discovering 3D Parts from Image Collections
Chun-Han Yao, Wei-Chih Hung, Varun Jampani, Ming-Hsuan Yang
Multiresolution Deep Implicit Functions for 3D Shape Representation
Zhang Chen*, Yinda Zhang, Kyle Genova, Sean Fanello, Sofien Bouaziz, Christian Hane, Ruofei Du, Cem Keskin, Thomas Funkhouser, Danhang Tang
AI Choreographer: Music Conditioned 3D Dance Generation With AIST++ (see the blog post)
Ruilong Li*, Shan Yang, David A. Ross, Angjoo Kanazawa
Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
Bangbang Yang, Han Zhou, Yinda Zhang, Hujun Bao, Yinghao Xu, Guofeng Zhang, Yijin Li, Zhaopeng Cui
VariTex: Variational Neural Face Textures
Marcel C. Buhler, Abhimitra Meka, Gengyan Li, Thabo Beeler, Otmar Hilliges
Pathdreamer: A World Model for Indoor Navigation (see the blog post)
Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, Peter Anderson
4D-Net for Learned Multi-Modal Alignment
AJ Piergiovanni, Vincent Casser, Michael S. Ryoo, Anelia Angelova
Episodic Transformer for Vision-and-Language Navigation
Alexander Pashevich*, Cordelia Schmid, Chen Sun
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Helisa Dhamo, Fabian Manhardt, Nassir Navab, Federico Tombari
Unconditional Scene Graph Generation
Sarthak Garg, Helisa Dhamo, Azade Farshad, Sabrina Musatian, Nassir Navab, Federico Tombari
Panoptic Narrative Grounding
Cristina González, Nicolás Ayobi, Isabela Hernández, José Hernández, Jordi Pont-Tuset, Pablo Arbeláez
Cross-Camera Convolutional Color Constancy
Mahmoud Afifi*, Jonathan T. Barron, Chloe LeGendre, Yun-Ta Tsai, Francois Bleibel
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Shumian Xin*, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul P. Srinivasan, Jiawen Chen, Ioannis Gkioulekas, Rahul Garg
COMISR: Compression-Informed Video Super-Resolution
Yinxiao Li, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, Peyman Milanfar
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul P. Srinivasan
Nerfies: Deformable Neural Radiance Fields
Keunhong Park*, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, Ricardo Martin-Brualla
Baking Neural Radiance Fields for Real-Time View Synthesis
Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec
Stacked Homography Transformations for Multi-View Pedestrian Detection
Liangchen Song, Jialian Wu, Ming Yang, Qian Zhang, Yuan Li, Junsong Yuan
COTR: Correspondence Transformer for Matching Across Images
Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, Kwang Moo Yi
Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R. Qi, Yin Zhou, Zoey Yang, Aurélien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, Dragomir Anguelov
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
Fait Poms, Vishnu Sarukkai, Ravi Teja Mullapudi, Nimit S. Sohoni, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, Leonidas J. Guibas
SLIDE: Single Image 3D Photography with Soft Layering and Depth-Aware Inpainting
Varun Jampani, Huiwen Chang, Kyle Sargent, Abhishek Kar, Richard Tucker, Michael Krainin, Dominik Kaeser, William T. Freeman, David Salesin, Brian Curless, Ce Liu
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-Based Optimization
Cheng Zhang, Zhaopeng Cui, Cai Chen, Shuaicheng Liu, Bing Zeng, Hujun Bao, Yinda Zhang
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, Angjoo Kanazawa
Workshops (only Google affiliations are noted)
Visual Inductive Priors for Data-Efficient Deep Learning Workshop
Speakers: Ekin Dogus Cubuk, Chelsea Finn
Instance-Level Recognition Workshop
Organizers: Andre Araujo, Cam Askew, Bingyi Cao, Jack Sim, Tobias Weyand
Unsup3D: Unsupervised 3D Learning in the Wild
Speakers: Adel Ahmadyan, Noah Snavely, Tali Dekel
Embedded and Real-World Computer Vision in Autonomous Driving (ERCVAD 2021)
Speakers: Mingxing Tan
Adversarial Robustness in the Real World
Speakers: Nicholas Carlini
Neural Architectures: Past, Present and Future
Speakers: Been Kim, Hanxiao Liu Organizers: Azade Nazi, Mingxing Tan, Quoc V. Le
Computational Challenges in Digital Pathology
Organizers: Craig Mermel, Po-Hsuan Cameron Chen
Interactive Labeling and Data Augmentation for Vision
Speakers: Vittorio Ferrari
Map-Based Localization for Autonomous Driving
Speakers: Simon Lynen
DeeperAction: Challenge and Workshop on Localized and Detailed Understanding of Human Actions in Videos
Speakers: Chen Sun Advisors: Rahul Sukthankar
Differentiable 3D Vision and Graphics
Speakers: Angjoo Kanazawa
Deep Multi-Task Learning in Computer Vision
Speakers: Chelsea Finn
Computer Vision for AR/VR
Speakers: Matthias Grundmann, Ira Kemelmacher-Shlizerman
GigaVision: When Gigapixel Videography Meets Computer Vision
Organizers: Feng Yang
Human Interaction for Robotic Navigation
Speakers: Peter Anderson
Advances in Image Manipulation Workshop and Challenges
Organizers: Ming-Hsuan Yang
More Exploration, Less Exploitation (MELEX)
Speakers: Angjoo Kanazawa
Structural and Compositional Learning on 3D Data
Speakers: Thomas Funkhouser, Kyle Genova Organizers: Fei Xia
Simulation Technology for Embodied AI
Organizers: Li Yi
Video Scene Parsing in the Wild Challenge Workshop
Speakers: Liang-Chieh (Jay) Chen
Structured Representations for Video Understanding
Organizers: Cordelia Schmid
Closing the Loop Between Vision and Language
Speakers: Cordelia Schmid
Segmenting and Tracking Every Point and Pixel: 6th Workshop on Benchmarking Multi-Target Tracking
Organizers: Jun Xie, Liang-Chieh Chen
AI for Creative Video Editing and Understanding
Speakers: Angjoo Kanazawa, Irfan Essa
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Speakers: Chelsea Finn Organizers: Fei Xia
Computer Vision for Automated Medical Diagnosis
Organizers: Maithra Raghu
Computer Vision for the Factory Floor
Speakers: Cordelia Schmid
Tutorials (only Google affiliations are noted)
Towards Robust, Trustworthy, and Explainable Computer Vision
Speakers: Sara Hooker
Multi-Modality Learning from Videos and Beyond
Organizers: Arsha Nagrani
Tutorial on Large Scale Holistic Video Understanding
Organizers: David Ross
Efficient Video Understanding: State of the Art, Challenges, and Opportunities
Organizers: Arsha Nagrani
* Indicates work done while at Google
SkyNet isn’t coming for you — but excel might be

A few years ago, I was working on an artificial intelligence startup called AlphaMorph. We worked on a kind of AI known as genetic algorithms (think evolution, not brains) and were using the wonderful little game Airships: Conquer the Skies as a testing environment. The goal of the game was to design digital airships and command them to victory. Each ship was made of dozens of components (cannons, sails, balloons) which the player could link up.
In one of our trials, we gave the algorithm a simple instruction: defeat as many enemy vessels as possible (in 1v1 rounds) with the cheapest possible airship. After generations of trial and error, and days of computer time, AlphaMorph produced its answer: a tiny ship which would fly above enemies, attach itself via harpoon, and fire missiles point blank into their hull.
This strategy was devastatingly effective — but it was also suicidal.
In nearly every trial, the AI-produced ship would destroy itself only seconds after the enemy fell. To our human eyes, this appears to be a failure. Afterall, in both the game and real life, a “victory” which requires self-destruction is hardly a victory at all. But to the AI, this solution was ideal. Its instructions were to destroy as many ships as possible as cheaply as possible. It did that — and only that.
Self-survivability was not included in the instructions, and so it was ignored.
In the world of AI, the definition of “intelligence” is fairly controversial. To most people, intelligence means adaptability, some degree of self-awareness, and the ability to carry prior knowledge into new situations. If applied to AI, however, barely any (if any at all) machine intelligences would meet those requirements.
From an enemy in a video game, to an excel model, to a genetic algorithm, the vast majority of “AIs” in use today are what could be called “dumb.” Most every video game AI simply runs down a checklist of “if-then” reactions to the player, most excel algorithms are little more than equations calculated in series, and genetic algorithms are no more intelligent than Darwinian evolution. In short, most AIs cannot adapt, they cannot change their program, and they cannot truly learn or remember; it’s certainly artificial, but it’s not particularly intelligent after all.
But that doesn’t mean “dumb AI” is weak — or safe.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
3. Machine Learning by Using Regression Model
4. Top Data Science Platforms in 2021 Other than Kaggle
Every day, across the world, millions of decisions are outsourced to algorithms (one kind of “dumb AI” we discussed above). Excel spreadsheets run numbers and tell analysts how an advertisement, service, downturn, or market shift impacted business. And, because nearly every institution we have is dedicated to generating profit, most of these dumb AIs spend their days telling human beings what is or is not profitable.
Moral considerations never enter these models. Algorithms, like all dumb AI, are only able to play by the rules we write and strive for the goals we set. If a corporation uses algorithms to increase profits, they will do just that — no matter the cost.
This is dangerous for two reasons. For one, it means giving immense power to undemocratic, unintelligent, and truly amoral machines. For another, it absolves individual humans of having to face moral choices. A rideshare company’s pricing algorithm can determine, rightly or wrongly, that a surge in requests for rides is an opportunity for profit, and increase the cost as a result. Done without direct human oversight, this allows companies like Uber to extract as much profit as possible from, say, a concert which has recently ended and generated a large pool of demand in one area. No person is asked to justify the increases, and if they were, they could just point to the math and shrug.
In most situations, exporting such a decision to an algorithm (or any form of dumb AI) is mostly just annoying. Sure it’s no fun to pay more to leave, but it’s hardly life and death. Except, one day, it was.
After a group of knife-wielding terrorists drove into crowds on London Bridge, Uber’s algorithm noticed an opportunity. Hundreds of requests came surging in for rides away from the danger and its aftermath, and the algorithm dutifully increased rates as a result. What had been an annoyance in one situation (likely the situation Uber’s developers had considered when programming this AI) became a robbery in another — your money or your life.
After this incident, there was a massive and understandable backlash against Uber. It’s not clear whether their surge pricing algorithm was changed in any way, but at least the harm it caused was noticed, highlighted, and organized against. But this is an extreme example of harm done by dumb AIs. The vast majority of similar decisions, each with the capacity to do damage and each with little direct human oversight, are never acknowledged by their victims or perpetrators.
What about a salary sheet that recommends who gets raises? A productivity algorithm that leaves a warehouse understaffed? A supply chain monitor that proposes leveling another acre for palm oil? Who objects to, or even notices, the AIs making those calls?
Millions of little choices, all made by dispassionate, unintelligent, and unbiased machines completing their instructions perfectly every day. Each one is told to maximize shareholder profit and each does so immaculately — until one day we are left with an uninhabitable planet, replete with suffering, and containing whatever remains of the servers housing those imagined profits.
The idea of a human-like intelligence deciding humanity should be destroyed is romantic. It’s roughly akin to a malevolent god deciding to punish humanity for our sins.
The more probable horror, however, is far less story-esque. Dumb algorithms — those which may adapt but ultimately seek to achieve very simply instructions — are far more likely to be our downfall. The instruction “generate profit” or “create paperclips,” if given without sufficient limitations (limitations humans may not be able to predict, much less implement) could result in any number of horrors all wrought in pursuit of the simplest goals. Human lives, a habitable climate, or concern for ecologies do not matter to algorithms by default. They have to be coded in, either as an instruction or as a rule — and if we aren’t comprehensive enough, they may well be ignored.
AlphaMorph was not evil or even wrong, it was misled. I misled it. By providing incomplete instructions, I left the algorithm with an opportunity to find “solutions” no human would accept.
Similarly, it’s not that excel, or evolution, or programming, or math is evil, it’s that we do not understand the power we’ve given it, the holes in our instructions, or the limitations of our code. Any human future will need some kind of dumb AI assistance. Whether post-apocalyptic or hyper-futuristic, dumb AIs are excellent at completing repeated tasks or helping humans find optimal solutions. But they are a tool, not a cure-all.
Intelligence has the capacity for fundamental re-evaluation and change. Algorithms do not. An intelligence might be wrong, or even evil, but “dumb algorithms” are something much more dangerous.
They are inevitable.
If given the power, they will simply and unthinkingly execute their instructions; if they execute us in the process, they won’t even notice.
Special thanks to Phasma Landrum for suggesting this topic.
Don’t forget to give us your 👏 !




The Dangers of Dumb AI was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

In the future, advanced cybersecurity solutions will be created by combining artificial intelligence with human intelligence. Artificial intelligence will make it easier to combat cybercrime and cyberattacks. AI has a lot of potential in the transportation and manufacturing industries.
Artificial intelligence will spur innovation and have a big impact across a variety of industries.
Artificial intelligence has had a big impact on a range of industries in recent years and will continue to do so in the future. As a consequence of the pandemic-induced acceleration of technology adoption, many businesses, both private and public, are utilising AI for their advantage and growth. In recent years, AI has enabled many advances and accelerated the spread of technologies such as IoT, robotics, analytics, and voice assistants.
Artificial Intelligence’s Impact
Artificial intelligence will make it easier to combat cybercrime and cyberattacks. AI has a lot of potential in the transportation and manufacturing industries. In the coming years, we may witness optimal advancement and commercialization of smart and autonomous vehicles. Self-driving cars are currently on the market, but in the next two to three decades, more people will use them. AI will also help the manufacturing business.
Thanks to artificial intelligence, healthcare systems will be able to track and monitor patients in real-time, as well as get genetic data and learn about each person’s lifestyle. Algorithms will be in charge of detecting diseases and making relevant recommendations.
Is Artificial Intelligence (AI) Going to Destroy Human Labor?
This is a concern that has hovered over artificial intelligence for a long time. Elon Musk and Stephen Hawkings, among other experts and industrial giants, have warned mankind about the technology’s bad consequences and hazards. One of the most often claimed consequences is that AI will replace human labour, resulting in major job losses. This claim is grossly overstated, according to experts, and while AI may replace humans in some occupations, it will not replace the whole workforce. Picking and packing products, sorting and separating commodities, responding to recurring client inquiries, and other regular activities and repetitive operations are all part of the job.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
3. Machine Learning by Using Regression Model
4. Top Data Science Platforms in 2021 Other than Kaggle
Should We Be Worried About AI’s Future?
AMOLF’s Soft Robotic Matter section has published research demonstrating how self-learning robots can quickly adapt to changing circumstances. These little robotic components were connected together in order for them to learn to move independently.
As a result, AI may not be a threat to human life as a whole. However, there is a possibility that someone will make use of the technology’s capabilities to harm others. Combat robots, for example, might be used to deliver harmful intents via their algorithms. As a result, it will be critical in the next years to establish an ethical AI environment devoid of human prejudices, which may aid in development.
Don’t forget to give us your 👏 !
What role will artificial intelligence play in improving the future? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

Shoppers have been known to abandon their shopping carts seeing the long queues at the counters. In spite of the amazing strides the retail industry has seen, what customers want is freedom from the endless lines at the checkout counters for a seamless shopping experience.
Checkout-free technology has brought a new experience to the retail environment. The automated system recognizes products and bills the customer accordingly. This means less waiting time for the shopper and a quicker service as compared to conventional shopping checkout lanes.
Using AI-powered cameras and software, computer vision is changing the way people interact with the physical world. Computer vision and AI are ultimately going to have an impact that goes far beyond retail autonomous driving, manufacturing, offices, gyms to fundamentally alter and better the way we live.
What is Autonomous Checkout?
The system is making use of a combination of computer vision, affordable ceiling-based cameras, and a precise in-store navigation map to detect the actions performed by each customer entered.
Customers can have their faces scanned by facial recognition software before entering the store or are required to swipe a card before entering. By understanding the interactions of customers and seeing the movement of products is enabling a checkout-less experience. Whether in retail locations or worksites, users can grab a selection of items and walk away, while the system takes care of recording the transaction.
Using auto-checkouts in stores is a win-win strategy for both customers and retailers. More staff can be employed to help customers shop, rather than spending the company’s resources on cashiers’ manual labor. A frictionless shopping experience is a driving factor for retailers to strive for cashier-less stores.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
3. Machine Learning by Using Regression Model
4. Top Data Science Platforms in 2021 Other than Kaggle
How it Works
Session Start
Shopping sessions can start in a variety of ways depending on the retailer’s preference. In a standard setup, customers initiate a transaction at an entry gate using a personal QR code from an app. Facial recognition can also be used for identification. Other setups can be configured without an entry gate or even without an app.
Customer Detected
Upon entering the store, strategically placed cameras capture the scene. Deep learning models running on local servers to detect humans in these video feeds.
Anonymous Tracking
When a shopping session is started, customers are assigned a random ID. A central server uses this to track each shopper throughout the store as they pass through from camera to camera.
Product Selection
Using deep learning models trained on product and positioning data from Product Mapper software, the system determines when customers interact with products & whether to add or subtract that item from their cart.
Check-Out
Upon leaving the store customers are charged via their digital wallet, receiving a receipt via email or text. In other configurations, a POS kiosk may auto-populate the customer’s cart for checkout, allowing use of conventional payment methods such as cash, credit, etc.
Conclusion
The disruptive potential of AI-powered checkout systems is here for brick-and-mortar stores to adapt to this new shopping experience. Fewer cashiers reduced checkout lines and reinvented shopping carts will redefine the customer experience. Amplified by machine learning, image recognition, sensors, and deep learning algorithms, frictionless checkout systems are a long-lasting technology. Autonomous checkout technology will reduce labor costs, improve customer experience and improve profit margins for retailers.
Clearly, there is a need for autonomous checkout technology from both a shopper and retailer perspective. However, the major point of focus for retailers should always be the customer’s in-store experience and how they can enhance this through the implementation of autonomous checkout. By being able to improve this experience, shoppers will in turn value those brands that are taking extra steps to put the shopper’s needs first.
Don’t forget to give us your 👏 !
How AI powers Self-Checkout for Retail was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
I recently worked on an end-to-end project that involves accessing real-world data and information from an on-chain Ethereum smart contract. I’d like to explain the importance of this process for future applications as well as explain the process a bit as I find it extremely groundbreaking. I will be explaining this process following the Chainlink protocol architecture as that is what I had used learning the process.

The path that data takes from a regular (and often centralized) data source is this: Data Source API → External Adapter → Chainlink Job (Created by a node operator) → Chainlink Oracle smart contract (or aggregator contract) → Your smart contract trying to use this data for whatever purposes it needs.
Let’s chat about why this is initially interesting overall, but I’m sure as I explain the process, we’ll go into further use cases that underline why I use the word ‘groundbreaking’.
Why?
Smart contracts that live ‘on-chain’ need gas to be decentralized and to execute the operations and functions they were designed for. This ‘gas’ is comparable to computing power, or even more basically, plugging our computer into an outlet in the wall. Electricity flows through the outlet and into your computer and the computer uses that energy as fuel to run whatever code you write on your local machine.
So gas, is what makes the decentralized universe run as it gives incentive to any individuals who stake a token or miners in a blockchain network (which of course is dependent on whether that blockchain runs a proof-of-stake or proof-of-work algorithm).
In the end, this means it is extremely expensive to do operations that might take a lot of computing power. Protocols like Chainlink work to fix this issue by using their infrastructure to allow for these smart contracts to pull this data quickly in one inexpensive operation On-chain, while the bulk of the expensive computation is done Off-chain. For an example, think of how expensive running a large AI neural network is and how much computing power that can require. Wouldn’t you rather not take a mortgage on your home just to pay for the gas to run it once?
BONUS FEATURE: As Chainlink has leveled up, the architecture has gotten more efficient and more decentralized. When data passes through these aggregator nodes, the reason they are called ‘aggregator’ nodes is because they truly aggregate the data and basically check any data’s validity by running the data against other nodes around the world and reach a consensus on whether the data coming On-Chain for the smart contracts to use is accurate. I don’t feel a need to go further into why that is important.
Accessing Real World Data and Your External Adapter
Let’s get to this specific example and the technicals.
The data we want to reach is housed from an API that we can access. So, our next step is to build what is called an external adapter. This adapter itself is run as its own API through Node.js using Express and Typescript. We access the JSON response from calling the API and specify within our adapter the endpoints and information that we will ultimately be retrieving from the data source.

It’s pretty much that simple to draw from the API, now you have the data in your external adapter to use how you wish. I also want to mention that in this external adapter API, you could make it as large as a project as you wish, and for instance, here is where you could set up your AI neural network or some quantum computing algorithm if you wanted. Ultimately, the data that you are happy with here, you will be sending on its way for the smart contract to use.
Once the data is prepared and ready to send on its way, you must ‘dress up’ the data in the right way for a Chainlink node to read it in its own language. Thankfully, Chainlink makes this part pretty simple, as its fairly standard for most external adapters, through their templates which they offer up in their documentation (linked below in references)
Zoom! The data is now moving on to your chainlink node.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
3. Machine Learning by Using Regression Model
4. Top Data Science Platforms in 2021 Other than Kaggle
The Chainlink Node Operator And Oracle Contract
In this project, I set up my own Chainlink development environment and local Chainlink node for quick testing purposes. This is also technically good as the more nodes on the network push for the ideology of decentralization.
Once my node was up and running, I logged in as an operator and created what is called a ‘Bridge’. This Bridge basically just identified the external adapter I just wrote as an official adapter and made it readily available for my use in any ‘Job’ that I wanted to write. Just think of a Job as the translator between smart contracts and Typescript External Adapters.
To create a Job, we must write a Job spec, that basically just is a pipeline that we feed our data coming in through and makes it easier for the Ethereum (or whatever blockchain you are using) to understand your data.
In order to do this, we must place our Bridge adapter in the Job spec as well as other necessary Chainlink ‘Core’ Adapters which are there for us to use to complete any other operations on our data (i.e. converting our data to uint256 etc.).
In the past, this spec was written in JSON, but with the new versions of Chainlink, specs are now written in TOML, so read up on that if you’re interested in running nodes and creating your own jobs.
One last thing to note, is that here is also a good point to deploy your ‘Oracle Contract’, which you’ll need to successfully finish the job and you’ll also need it in the next step when referring to your job in your smart contract. Luckily, Chainlink also makes this fairly simple through a nice template in their documentation as well as it is a simple contract. You can easily deploy right from Remix IDE and then grab the contract address from Etherscan.io.
The Consumer Smart Contract
Finally, we’ve reached the destination.
Think of ‘Consumer Contract’ as just being the smart contract that is trying to access the real-world API data. There are great templates already out there for the parts of the contract that need to ‘grab’ the data from the Job spec as it runs through the Oracle contract (also in Chainlink documentation below).
You’ll just need to know enough solidity to write any functions that will pull the endpoints, or specific data from the JSON responses from the external adapters. Then feel free to do however you please with the data!
Conclusion
The future holds so many use cases for smart contracts and this idea of Oracles and basically bridging the scary gap of computation and data as we collect Off-chain and placing that On-chain for the blockchain to do its thing. The architecture of this process is always improving and being worked on every day. Another great benefit is that many of these Oracle protocols are ‘Blockchain-Agnostic’ meaning that they don’t rely on Ethereum specifically to succeed. New blockchains are being created all the time and this architecture is improving to be compatible with new blockchains all the time. This is awesome for true decentralization!
References
https://docs.chain.link/ — chainlink documentation
https://github.com/smartcontractkit/external-adapters-js — chainlink external-adapter typescript template-repo
https://www.gemini.com/cryptopedia/what-is-chainlink-and-how-does-it-work#section-where-do-link-tokens-fit-in — Better help in understanding the process of Chainlink or Other oracle services.
https://docs.chain.link/docs/fulfilling-requests/ — Fulfilling Node Requests and Oracle Contract Deployment
Don’t forget to give us your 👏 !
The Groundbreaking Bridge Between Real World Data and Smart Contracts was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Artificial Intelligence (AI) is everywhere — in our phones, in our offices, in our cars, and pretty much everything else one can imagine. So, it only makes sense this technology has made inroads into the world of e-commerce as well, which happens to be one of the most popular industries in the world at the moment. It is revolutionizing eCommerce for small and big businesses where it is being used by various retail companies to develop a better understanding of their customers.

Despite the popularity of the sector, it is starting to feel the need for better and advanced tools that can help address some of the more complex challenges. You would agree AI-powered commerce enables customer-centric online searches, identifies prospective customers, answers customers’ queries, simplifies sales techniques, establishes actual conversations with customers through chatbots, etc.
Suffice it to say that AI is more than ready to do that and so much more.
1. Efficient sales: The thing about the modern-day customer is that they are very finicky and thus, quite challenging to win over. Thankfully, artificial intelligence is well-equipped to take on this challenge; when integrated with the e-commerce retailer’s CRM system, AI tools can tap into other advanced tools such as voice input, natural language learning, etc. to drive better customer service operations via answering customer queries, identifying new sales opportunities, etc. While certain CRM systems integrated with AI may be able to handle only some of the aforementioned tasks, a newer crop of systems can successfully execute all these functions with absolute ease.
2. Improve customer targeting: Today, the market is brimming with avant-garde AI tools and solutions that empower e-commerce companies with exceptional data and intelligence to better target their audience and improve lead generation among other things. These AI solutions for e-commerce retailers’ sales, CRM, and marketing systems help generate a significantly better quality of leads by making use of the data captured from across the company’s systems. This data helps companies find high-quality prospects, which empowers their sales teams to garner new business and more sales.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
3. Machine Learning by Using Regression Model
4. Top Data Science Platforms in 2021 Other than Kaggle
3. Better levels of personalization: While it is decidedly not a new concept or expectation, the fact remains that the ability to deliver personalized services and offerings remains vital to the success of e-commerce endeavors. The new crop of AI tools can glean data from across several customer touchpoints and then analyze said data to empower companies with insights about how customers engage online, which channels they prefer, etc. With AI’s omnichannel approach, e-commerce retailers can continually track customers to develop in-depth customer profiles that are then leveraged to provide end-users not only a substantially more personalized experience but also one that is much more streamlined than before.
The need for convenience and better experiences is rather compelling and the emergence of e-commerce in the first place is a quality demonstration of that assertion. Now, e-commerce has served the world wonderfully well so far, but the sector is starting to feel the growing pressure for changes and advancement to deliver even better experiences. And let us not forget the coronavirus pandemic, which has further focused the spotlight on this industry. As the above discussion demonstrates artificial intelligence comes loaded with the potential to improve e-commerce in every way imaginable. Be it better customer service, improved processes, or enhanced sales — artificial intelligence can enable all that and so much more. So, your first step now should be looking for a reliable ecommerce web store development company with ample experience to help you embrace artificial intelligence and take your business to the next level.
Don’t forget to give us your 👏 !
Robust Ways to Leverage Artificial Intelligence In eCommerce was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

At Dashbot, we recently hosted a meetup in NYC to discuss brand strategies in conversational interfaces. As the space continues to mature, more brands are getting involved and moving from experimental to production deployments. We assembled a great group of industry experts to share their thoughts and tips for brands looking to build a chatbot or voice skill.
Our panelists included:
- Alec Truitt, Global Product Partnerships, Google Assistant
- Anamita Guha, Global Lead of Product Management, IBM Q
- Antonio Cucciniello, Senior Software Developer, Reprise Digital
- Brian Plaskon, Senior Product Manager, Realogy Holdings
What use cases are brands developing for?
Our panelists see a wide variety of use cases from customer service, productivity tools, and information sharing to entertainment and marketing initiatives.
At IBM, they work with everyone from individual developers to Fortune 20 enterprises. The most common use case, though, is customer care. Large enterprises go to IBM given their ability to handle sensitive data across industry and geographic regulations.
Google works with a similar range of users and enterprises. The use cases for Google Assistant Actions depend on the context — in the home (recipes, home automation), mobile (games, local search), or in the car on the go (communication, messaging).
Reprise Digital, a global marketing agency, tends to work with brands looking to experiment on a new platform, market their products, or provide information and FAQs. Given voice is a new platform, there are some set of brands that want to be first on it. We also see this frequently with innovation teams experimenting in voice. On the text chatbot side, Reprise generally sees brands looking to promote their products or answer FAQs.
Realogy, the real estate holding company for Century21, Coldwell Banker, Sotheby’s, and more, developed its own voice skill, AgentX. Agent X is a productivity skill that enables real estate agents to quickly get information, including their appointments, market research, and listing information — all without the need to open their laptop.
Tips from the experts — what works well for conversational interfaces?
Context is key
A common theme throughout the evening was the importance of context. Where is the user? What are they currently doing? What are they looking for or to do? What are the capabilities of the device?
In addition to the three contexts Alec pointed out earlier (in the home, mobile, and in the car), he recommended also considering when will the user interacts with the chatbot and how the user expects to interact with it. If the user is in the car, they cannot use their hands. If they are at home getting a recipe, having something visual can help. If the user wants to play a game, but is on a device without a screen, perhaps a quiz is better.
Whether the interface is voice enabled or text only is important. As Anamita points out, users talk differently than they type.
Trust can also be an important factor. As IBM works with many global enterprises handling sensitive data, one of the areas Anamita sees is that a user may be more likely to trust interacting on a computer, where identity can be more easily verified, rather than via voice.
Leverage the conversational nature of interfaces
Conversational interfaces are quite a bit different from websites and mobile apps — what works well in those may not work well in a chatbot or voice skill.
At Reprise, Antonio sometimes sees brands who want to port what they currently have on their website or mobile app to a chatbot or voice interface. Whereas the website is all about navigating from one link to the other to vertically drill into what the user is looking for, with conversation, a user should be able to say, or write, what they want and directly get to the information.
Similarly with Realogy, agents are looking for information that is stored in a variety of locations and want to be able to retrieve it quickly and easily. A powerful example of Agent X is when a listing agent is in a presentation with a seller and wants to know the average time on the market or average listing price for a property, they can quickly get the info, without the need to open a laptop and start searching.
As Alec adds, there is a low tolerance amongst users of voice skills. If the skill is not useful, or they do not see the value right away, they will jump to something else. If they see a great use case, they will invest the extra time. It is important not to replicate what you already have on your website or app, but to consider what will add value to the user and what is faster to use.
Keep it simple, provide guidance
Another common theme amongst our panels was to start simple.
As Alec pointed out, with voice, it is especially important to keep interactions simple rather than complex back and forths. For example, placing an order for food delivery from scratch can be rather complex. However, re-ordering a previous delivery is much easier, and better suited to voice. We see the same thing with the food delivery clients we work with. We also learned from our voice survey, that approximately 53% of purchases through voice interfaces is for food delivery.
In general, the process Alec sees developers follow with Google Actions is to first build the foundation and make sure the Action works, next layer in visuals and make it more interactive, and finally delight the user so they come back and re-engage.
Simplicity was also a key goal for Realogy. One of the most popular use cases is just looking up real estate listings. They plan to build new capabilities where it makes sense. They are not just doing voice for voice sake.
To get started, Brian recommends going through the design exercise at https://alexa.design/cdw and to read “ Understand how users invoke custom skills “ to add variety into the interaction model.
In addition to starting simple, it is important to let the user know what the chatbot or voice skill can do. While Alec suggested the initial interaction can intro what the chatbot can do, it should not do that every time. If the user comes back, allow the user to take the next steps. Anamita recommends including a “fallback” Intent to catch cases the chatbot does not handle. If the fallback is triggered, the chatbot could respond, “sorry I cannot do X, but I can do these six things.”
Personality can be important
Depending on the use case of the chatbot or voice skill, personality can be an important factor.
IBM has an “empathy suite” including a tone analyzer and personality insights. When implemented in a customer care chatbot, if a user says they are having a horrible day, the chatbot can understand that and provide a different experience.
As users become more comfortable interacting with chatbots and voice, providing a personality can be quite useful. As Anamita explained, initially chatbots were built for efficiency or to automate a task, but now people are creating relationships with them. Children are growing up with bots that have been anthropomorphized, like the Pepper Robot.
Whether to enable empathy or a personality in a chatbot comes back to context. Anamita sees teaching and therapy use cases as more suited for empathy versus something more transactional. As Brian added, real estate agents range from “Type A” to “Type A,” so they keep personality and cuteness to a minimum. Right now the goal is to be as helpful and productive as possible, but there is room for personality in the future.
At Reprise, copywriters try to come up with a voice for the brand — a name and description of the persona and how they would talk. They use this in all the copy as it is important for the voice of the brand to be the same across the entire experience, whether that is on the Internet or voice device.
In regards to using voice actors on Alexa or Google Home, the panel in general thought they could be beneficial depending on the use case. For example, Antonio pointed out that if a user were interacting with a Jimmy Fallon skill, they would probably be more engaged if it was his voice rather than the default device’s voice.
User acquisition and discovery are challenges
Our panelists generally agree that user acquisition and discovery are challenges.
Education is one of the underlying issues. Some users do not even know third party voice apps exist. As we noted in our earlier voice survey, one of the issues is users tend not to know what voice apps are even called.
Similarly, while Antonio finds users tend to not understand how to invoke the voice apps, improving the invocation can lead to increased acquisition. Associating the invocation name with the brand or something popular can help.
Making use of the “can fulfill” Intents on Alexa or Google Home can lead to increase acquisition too. If a user asks for something that matches a “can fulfill” Intent, the skill may be presented as a possible option to the user.
Discovery can depend on the use case. Anamita finds word-of-mouth tends to work when users are searching for chatbots for need or pleasure. If the use case is more transactional, the enterprise could suggest to the user to try the chatbot instead.
Even internal promotion within a company can be a challenge. At Realogy, there are a lot of competing internal marketing initiatives. What worked for Brian was to incentivize folks with device giveaways. He recommends channeling your internal game show host — “there’s a little Steve Harvey in all of us.”
Alec’s team at Google is working on solutions to improve user acquisition and discovery. They are not only looking to help with generating initial acquisition, but with retention as well to keep users coming back. One of the challenges is users sometimes do not remember how they found a particular voice app and then how to get back to it.
Analytics are essential
Our panelists all agreed analytics are important. As Alec pointed out, you need great analytics to identify what is driving usage and how to improve it.
Realogy uses Dashbot to gain insights into how agents are interacting with Agent X. They wanted to know if agents would know how to interact with the skill and which features were used more than others. Dashbot helped answer those questions. They also found there is a voracious appetite for new capabilities.
Through Dashbot, Reprise has also been able to improve engagement. They learned for one of their client’s Google Actions, that most of the Intents were not being used. It turned out the issue was with all the overly complicated Intents. Based on the analytics, they launched a new version that was much more simplified.
In addition to analytics, Anamita recommends adding a feedback loop directly in the experience. Most of IBM’s internal chatbots include a thumbs up/down prompt asking the user if the chatbot answered the question right or provided the info they needed. At Dashbot, we are able to show these customer satisfaction (CSAT) scores, and the paths leading to them, to help enable improvements in the response effectiveness.
What’s next
We asked our panel if they had any thoughts on the future of the space. There was a great sense of optimism and excitement for the future.
Anamita predicts digital humans becoming more of a reality — having interfaces with human facial reactions.
Brian is looking forward to a generational leap in the device capabilities — what he likens to going from one game console to the next.
Antonio sees users becoming more comfortable with having voice devices in their homes as well as areas for improvement for the space to take off even more. The three main areas are education (knowing how to use the device), discovery (how to find what is needed), and user experience (providing value to users). User experience is the most important to get people to adopt the devices.
Alec envisions a blending of voice apps and chatbots to provide the best experience depending on the context, rather than separate experiences. Voice can be the bridge to jump from the starting point to the finish.
At Dashbot, we are very excited about the future of conversational interfaces. We look forward to seeing what enterprise brands continue to develop.
Watch the full panel
https://medium.com/media/64d93c231cc35a6fd465d9fa414dcca4/hrefAbout Dashbot
Dashbot is a conversational analytics platform that enables enterprises and developers to increase user engagement, acquisition, and conversions through actionable insights and tools.
In addition to traditional analytics like engagement and retention, we provide conversation specific metrics including NLP response effectiveness, sentiment analysis, conversational analytics, and the full chat session transcripts.
We also have tools to take action on the data, like our live person take over of chat sessions and push notifications for re-engagement.
We support Alexa, Google Home, Facebook Messenger, Slack, Twitter, Kik, SMS, web chat, and any other conversational interface.
Brand Strategies for Conversational Interfaces was originally published in Chatbots Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

Is a robot going to take my job? We cover AI programs like chatbots can make our employees a little nervous and how you lead change change.
AI Chatbots in Healthcare: Transform Patient’s Engagement with Healthcare Providers

Chatbots are replacing phone call-based customer service in various sectors. In the healthcare industry is opting Chatbots to help patients in resolving their concerns faster than traditional methods. In the healthcare sector, the patient’s experience remains at the top priority. These days the patient-driven healthcare environment is helping the patient to make better decisions.
To remain spontaneous, it is the time for the healthcare services to embrace consumer readiness for digital communication via AI chatbot. This can help to deepen patient engagement that leads to better health outcomes. With AI Chatbots healthcare systems can accelerate the leap to add values for patient healthcare. Healthcare Chatbots industry is booming at a CAGR of 20.5% to Estimated $542.3 million Growth By 2026.
Chatbots in healthcare can offer the best health care service. Smart Chatbots can help a patient to schedule a follow-up instantaneously. It offers distinctive automated conversational interactions with quality experience of care. A chatbot is a way ahead to improve 24/7 customer service and assist patients with processing every service request faster than ever before.
Challenges in healthcare
Healthcare is all about offering the services to the patient without any delay or any compromise. Healthcare service providers can implement the Chatbot services from scheduling an appointment to paying bills.

Chatbots make it simple for patients to connect anytime. It is the best way to ultimately deliver quality healthcare that surpasses patient expectations. These days app development services are addressing concerns in healthcare while overcoming the tedious challenges.
Payment Processing
In healthcare collecting payment is more challenging. These days’ patients are becoming responsible for a larger portion of their medical bills. If you want to increase the speed and amount of your collections, you should integrate chatbot for dealing with your patients.
Patient Experience
In recent years the landscape of healthcare services has experienced some significant changes. The patient experience is more demand for a better service provider. Healthcare service provider faces tougher competition in attracting and retaining patients. Chatbot services help to match the level of the patient experience.
Effective payment model
In healthcare payers and patients always demand a new payment model for better services. Chatbots can be helpful to reduce cost and increase service quality. AI chatbot can encourage healthcare providers to coordinate services and promote preventive care to patients.
Functioning huge data
In healthcare data is being generated in huge amount. It is very challenging to harness the power of data and generate accurate insights into the patient. In this case, Chatbots can use to optimize the patient experience.
Some use Cases for Chatbots in Healthcare Sector
Chatbots continue to gain grip in the healthcare sector to redefine healthcare industry. Here is a look at those use cases in healthcare.

1. Customer Service
Chatbot helps the users to navigate the site or troubleshoot a minor problem. Chatbots can be helpful for users to schedule appointments, issue reminders, or refilling prescription medications.
2. Patient Engagement
Chatbots can keep constant contact between patients and healthcare service providers. Chatbots are designed to offer accurate suggestions related to the patients’ interest. The chatbot assists the healthcare service provider to answer the question for further patient’s engagement.
3. Voice assistants
Chatbots can also provide voice assistance to patients for better guidance and outcomes. Chatbots having spoken conversations with patients offer the best way to tackle any size of patient’s problems. The voice technology integrated with the chatbot is an innovative way to connect the patient or the concerned person.
4. Keep patient update
A chatbot can help patients prepare for any size of surgery or operation beforehand. After a patient makes an appointment, a chatbot gets in touch via text message or email to the patient. With the concern expert details, it will deliver educational materials related to the surgery. This is a new way to address any patient. This will keep the patient and family to remain updated till the last moment.
Final thoughts
With best chatbot service provider your patient will not look elsewhere for a better option. A chatbot is the best option to eliminate human bias from interactions. With natural language processing, the Chatbots can increase the number of valid responses through the conversation.
With time the healthcare industry continues to embrace Chatbots to improve the health-related services. AI Chatbots are the best way to drive the consumer-centric patient expectations to deliver quick customer services. Chatbot development services are on a hike these in the healthcare sector focusing the patient services. The Chatbot services offered can be asked for medical advice, carry out administrative tasks, or consulting experts directly.
Overcoming the Patient Healthcare Challenges with AI Chatbots was originally published in Chatbots Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

The educational sector has undergone massive changes post the proliferation of internet services in learning.
It will not be an exaggeration to say that they have completely changed the way students of all ages study, and the overall landscape of education has evolved for good.
With Education App Development Companies coming in, there are a host of online educational mobile apps for readers of every age. Schools also recommend online educational mobile app these days to reinforce and supplement in-class sessions.
Research suggests that the size of educational mobile apps is going to rise by CAGR of more than 27% by 2022, which marks it as one of the fastest-growing segments in mobile apps.
Home-grown apps like StuDocu and Byju have also witnessed exemplary growth in the last five years and is turning out to be the primary source of learning outside classes for all kinds of courses.
Some Factors That Govern the Impact of a Session, Online, as Well as In-Class, Are:
1. 360-degree view of the overall subject — Teachers who leave open ends while teaching often leaves students confused.
When a person learns, they develop a mind-map of the concept. When the mind map is incomplete, learning is fraught with confusion.
2. Manner of Teaching — Some teachers have a habit of giving interesting examples to teach. Some others make learning extraordinarily interactive and fun.
3. Engagement — When students engage themselves during the session, they tend to learn better.
4. Feedback — A student remembers positive as well as negative feedback. Research suggests that feedbacks help reinforce a person’s mind-map. Examinations are the traditional feedback mechanism; in the case of app- based learning, they are online assessments.
The solutions that are currently available in the market rely on coded content, embedded videos, and paid manual support to enhance the teaching experience.
This is a gap that is still unaddressed and also a massive opportunity for improvement and innovation in the sector.
Quality of content in training may be excellent, but it can never replace that component of personal approval that a learner seeks to reinforce their mind-map.
Online mobile education is just a supplement and not a replacement to in-person education due to these very reasons in the present scenario.
Chatbots are an artificial intelligence-based solution that relies on natural language processing and native language generation to address certain aspects that existing mobile apps are missing, for e.g., Instagram bot.
Chatbots act as an online representative that may answer some of your questions.
The best success story about chatbots in present times is their usage by financial organizations to address specific client requests without having to call or visit a branch.
The chatbots are also widely used in scenarios that have intensive use cases developed traditionally. The reason is that they rely heavily on historical data and the flow of conversation.
An advanced version of a chatbot is Amelia that has received a lot of acceptance across domains.
Chatbot uses the Robotic Process Automation methodology in tandem with natural language processing to provide better customer experience while also gathering useful insights for the provider.
Now, coming back to the education sector where a real-life human teacher imparts its learnings to pupils through innovative methods and further reinforces it by asking and answering questions, a chatbot might work like magic.
To Base This Claim, Let Us Compare the Gaps in Educational Apps and Chatbot Offerings

1. 360-Degree View: A trainer uploads a video of an exhaustive lecture to explain a concept. The difference comes when a student is faced with a doubt that they cannot ask anyone online.
The chatbot window pops up and asks — what can I do for you today? The AI-based tool has already recorded the current context to answer the question.
This tool has trained on this particular topic through training datasets having a size of several terabytes and has most likely developed a good understanding.
If not able to answer, it says — “I am sorry, but you may have to reach out to an expert on this.” Voila! That is how we upsell.
2. Teaching Method — During the course, the chatbot seeks student feedback. The student shares feedback, and the chatbot utilizes its intelligent system to suggest — Would you like to refer courses from another faculty? Would you like to change the language mode?
The student can have a better learning experience than it would have had earlier. If the student is not satisfied with the resolution, chatbot connects him to a manual expert again.
3. Engagement — The student is faced with doubt in the middle of the training. He types the same in the chatbot that is present to the right side of the training window.
The chatbot utilizes its expansive knowledge in this context to answer and also suggests additional training to further brush up on the concepts.
The student can clarify small doubt without having to google into more pages — a straight cut method to retain student attention and reinforce learning with zero confusions.
4. Feedback — At the end of the course, the student is asked to give a small test to check his understanding. Unlike a traditional MCQ window, the questionnaire is administered by the chatbot.
When a student provides the wrong answer, it explains the reason why this answer is wrong and the best way to approach such questions for future references.
Once the training ends, it gives a final score and uses its intelligent model to suggest more courses to strengthen the student’s learning.
Using chatbot enables the consumer to have a better experience and also allows the provider to receive better feedback on their courses.
Chatbots can also be offered to students to connect with them on a personal level and counsel them on things that are bothering them or making individual decisions.
Benefits That a Chatbot Can Offer in Educational Mobile Apps

- Answering questions that a child may not be able to ask in a classroom setting due to peer pressure and fear of mocking by teachers and friends.
- Slow learners can attend the same training multiple times and keep brushing up on doubts and confusion to get at par with others.
- Fast learners can seek chatbot recommendations to understand what courses they may take next instead of waiting for it in classrooms. They can also ask questions such as the topics that can enable them to grow in a specific area of interest or training module to answer particular questions.
- Students at the tender age can rely on the chatbot to seek answers that may not have been addressed by their parents or teachers.
- Students who have a habit of asking too many questions can happily tinker with the chatbot to satisfy those inquisitive pangs now and then.
- Customization of chatbot will enhance the comfort level and engagement of the student at every age.
- A chatbot can turn to be a personal counselor to children at a crucial stage that may decide how they may develop their careers.
- A chatbot can be a personal assistant that helps the child plan their courses to complete all topics before the d-day.
- A chatbot can seek student feedback through the click of a button for improvements. It can also be used to design the student profile to guide them in the best way possible.
Things You Need to Take Care for Ensuring That Chatbots Can Add Value to the Existing Offerings
- Training and language model should be robust and exhaustive. A poorly trained system is even worse for a student than no chat support. Reason being that it may confuse children or portray the entire app solution as flawed and inefficient.
- The chatbot should not slow down the overall system. Integrating a chatbot into the existing system should be seamless, so it does not lead to other performance issues in the system.
- Security is a concern that has to be taken care of at all times. Chatbots should be galvanized against misuse by hackers since they are directly deriving information from the core database to learn from every experience. The chatbot should be able to identify a malicious user and notify the security team.
Conclusion
Educational Mobile apps have only touched the tip of the iceberg in terms of value addition and contribution.
Many remote villages across India rely on online education to learn. The introduction of chatbot needs to be such that it percolates to every level of users.
With time and increased penetration, businesses are bound to uncover further innovative ways to enhance the educational experience and make a social difference that they are capable of.
***********************************************
Author Bio:-
Harikrishna Kundariya, a marketer, developer, IoT, ChatBot & Blockchain savvy, designer, co-founder, Director of eSparkBiz Technologies, a Mobile App Development Company. His 8+ experience enables him to provide digital solutions to new start-ups based on IoT & Blockchain
How Chatbots can be a Game Changer for Educational Mobile Apps? was originally published in Chatbots Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
A funnel-driven approach to Messenger bots for lead generation
Testing. Testing is one of the main things I have devoted my energies to in the past year. Testing assumptions. Testing concepts. Testing product increments.
Incrementalism is key whenever you are building something that does not exist yet.
When we started Visualbots, a chatbot tool for lead generation, the assumptions to test were many. The industry was still in its infancy and marketers were not used to tools like ours. And we did not know which bot design and optimisation strategies would have worked the most.
But we were sure there was a key product assumption to test:
“Can Messenger bots be used for lead generation and deliver better results than the two main substitute products (namely landing pages and lead ads)?”https://medium.com/media/2b9ba61cbf6a3149ce3c6fb7c886c6be/href
In order to prove this assumption, we have worked with tens of early adopters across different industries spending tens of thousands of euros, following this process: we transformed an existing landing page into a chatbot, we run Facebook advertising campaigns on the bot and we measured the performance of the full funnel, with the ultimate goal to achieve a target conversion rate (see one of the first examples below).
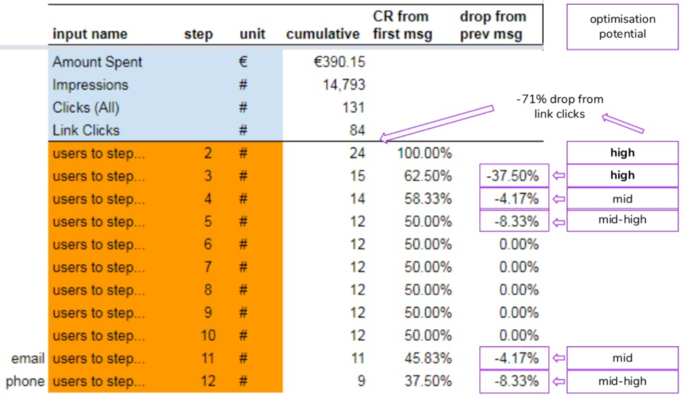
This has allowed us to gather a lot of data and generate expertise on how the lead generation bot funnel works on Messenger. And I am writing this article to share some of the lessons we have learned on the three following points below:
- The Messenger bot funnel
- The Messenger bot KPIs
- Optimising Messenger bot KPIs
Enjoy the article.
The Messenger bot funnel
As every user acquisition activity, the messenger flow can be represented as a funnel, which consists of 3 main steps:
- Acquisition
- Activation
- Conversion
1. Acquisition (= the ad)
Acquisition refers to the marketing channel used to send traffic to the bot.
In our case it is constituted by the Facebook click-to-messenger ad used to drive traffic to the Messenger chat.

2. Activation (= the welcome message)
Activation refers to the first meaningful action accomplished by the user that starts to chat with the bot. In our case it consists in the interaction with the welcome message of the bot.
The welcome message is the first thing a user sees when they encounter the Messenger bot from the ad.
It is technically a part of the ad itself, but we always analyse it separately, given it has its own characteristics and optimisation techniques.
3. Conversion (= the bot body)
Conversion refers to reaching the goal of the bot.
In our case, since we are talking about lead generation, it typically consists in gathering an email, after multiple qualification questions contained in the “bot body” have been replied.
The Messenger bot KPIs
Each step of the bot funnel has its own KPI. The main ones we look at are:
- cost per click
- welcome message conversion rate
- lead conversion rate
Below you can find more details about each KPI.
1. Acquisition KPI (= cost per click)
The main KPI we use is cost per click (CPC). It indicates how costly a click sending traffic to the ad is.
This KPI is almost totally dependent on the ad setup itself, so that the actual content of the bot does not really matter here.
The formula is the following:
cost per click = amount spent/ clicks
A reasonable range of values for the metric is between 0.20€ and 0.40€.
We have seen cases in which the price was much lower, which normally translated in a very low lead quality, or higher, sometimes leading to better conversion rates down the funnel that compensate for the higher cost of traffic acquisition.
2. Activation KPI (= welcome message conversion rate)
The main KPI we use is the welcome message conversion rate. It indicates how many people that have seen the welcome message have actually interacted with it, initiating the conversation with the bot.
This KPI mostly depends on the consistency between the ad text/ image and the content of the welcome message and the way the message itself is written (e.g. short rhetorical questions normally work better).
The formula is the following:
welcome message conversion rate = conversations started/ link clicks
The “Conversations started” metric refers to the number of times people started messaging your business. It includes conversations with new users as well as previously engaged ones (in that sense being different from Facebook´s definition of Messaging Conversations Started).
The “Link clicks” metrics refers to the number of clicks that led users to open the chat (in the same way as it is defined by Facebook). We prefer to use this metric, rather than normal clicks, so that we can exclude the effect of people clicking on parts of the ad that do not link to the chat, such as the page name.
A reasonable range of values for the metric is between 25% and 50%.
3. Conversion KPI (= lead conversion rate)
The main KPI we use is the lead conversion rate. It indicates how many people that started interacting with the bot ultimately left their more precious personal information (e.g. an email or a phone number), which are typically asked at the end of the funnel.
This KPI depends on how the whole funnel is structured, on the length of the flow and the way the personal information are asked.
The formula is the following:
lead conversion rate = leads/ conversations started
The concept of “Lead” varies greatly from company to company, but can be normally defined as a users that replying to the most important qualification question in the funnel.
Also defining a range for this metric is really difficult, since it varies a lot depending on the industry.
A reasonable range of values for a mid-long qualification funnel (i.e. with more than six questions) is between 25% and 50%.
But it can easily skyrocket above 75% in case of really high performing funnels.
Optimising Messenger bot KPIs
Before we go into the technicalities of how to improve the KPIs above, there is a main concept to keep in mind when creating and optimising a Messenger bot built for customer acquisition purposes:
You need to create consistent ad-to-bot experiences.
The ad and the bot needs to be conceived together, since there is no way you can start to improve the bot if the ad is not consistent with it. You would simply receive poor traffic that you will not be able to optimise for.

We have learned this the hard way, when the first tests were not producing the expected results. And the first signal of it was a really low welcome message conversion rate (i.e. only a few people interacting with the Facebook ad started to engage with the bot).
To understand the reasons why it was happening we did multiple UX tests with the bots, asking users to go through the whole funnel and tell us what they were expecting, step after step. It clearly emerged that the first reason people dropped was that what they received on the chat was not what they were expecting.
And this happened because who was doing the ad (the tester) was different from who was creating the bot (us).
That´s when we understood that, before even building the bot, we needed to think at the whole funnel together, beginning from the ad (and as a consequence we stated designing ads together with the bot — using this super cool tool for ad mockups).
Having said that, we can now go more into the details of what to look at when improving the different steps of the funnel.
1. Optimising the acquisition KPI (= cost per click)
These are the key questions we ask ourselves when the ad is not performing as intended (i.e. CPC consistently out of the expected range).
- Are you using Messages objective campaigns (campaign level optimisation)?
In our tests, they have proven to perform consistently better than other campaigns, including conversion campaigns.
- Are you using the right audience (ad set level optimisation)?
This has revealed to have a huge impact on the performance of the ad, as it happens in any other type of Facebook campaigns. The only aspect worth mentioning here is that a good optimisation technique is the following: after that a good number of conversations has been collected, you can create lookalike audiences to target people similar to the ones that already chatted with your bot. And this works pretty well.
- Are you using a low effort call-to-action (CTA) (ad level optimisation)?
In our tests, CTAs implying high potential effort for the user (e.g. “Send message”) performed worse than low effort ones (e.g. “Learn more”).
2. Optimising the activation KPI (= welcome message conversion rate)
These are the key questions we ask ourselves when the welcome message is not performing as intended (i.e. conversion rate consistently below 25%).
- Is your welcome message content consistent with the ad text and image?
As highlighted before, the main reason for bot acquisition campaigns to fail is that the ad and bot experience have not been thought together. Align the content of the ad with the one of the welcome message.
- Are you your asking a low effort question?
The welcome message role is essentially to ask the user to opt in the conversation with the bot. As a consequence you want to minimise friction as much as possible. And the way the message is phrased has a big impact. As michael highlights in his article, low effort asks work well, especially if they are in the form of rhetorical questions. Examples could be “Do you want to start?” or “Do you want to receive a free coupon code?”.
3. Optimise the conversion KPI (= lead conversion rate)
Being the concept of lead different from company to company, it is difficult to abstract lessons on how to optimise this KPI. Please keep that in mind when reading the key questions we ask ourselves when the lead conversion rate is not performing as intended (i.e. conversion rate consistently below 25%).
- Is the conversation building enough trust for the user to leave its contact details?
While carrying out our tests we realised something we had not expected before. We initially moved from the design assumption that shorter bots would have performed better than longer ones, since users would have gone through less steps.
But these short bots were not performing as expected, and removing questions produced even worse results. When we run UX tests we started receiving comments like the following:
“Feels like it hasn’t been enough questions to give out email address”
“How is this gonna provide me a personal quote with such a limited number of information given?”
It paradoxically seemed that users expected many questions before they could consider the bot reliable and decide to provide their personal details. In other words:
Questions build trust
The reality is indeed that the bot funnel of a lead generation bot looks more like the one you can see below.
- Are you explaining why you are asking for the personal information?
Before you ask for an email or a phone number, is always a good practice to explain why you need such information and what will happen after the user submits it, including when they will be contacted, by whom and for which reason (e.g. “We will send you a custom quote”, “We will book a visit in our apartments for you”).
- Are you providing any incentive?
It is a good practice to provide an incentive for the user to leave his personal details, such as a free quote, sample or a high quality content. This can be allowed already at the ad level and emphasised on the welcome message, but should ultimately product gains at the lead conversion level.
These are some of the lessons that we have learned over the last year while approaching Messenger bots as funnels and optimising them in a data-driven fashion (some further insights here).
I hope this will be helpful for you as well.
Have a good journey,
— Livio
14/12/2018
> Disclaimer: this article has been published a year after it was originally written. In the meanwhile, the project Visualbots has been discontinued and many things have changed in my life and in the chatbot landscape. I am sharing this article in the hope that the insights gathered in over one year of activity could still be useful for the Messenger marketing community. <
A funnel-driven approach to Messenger bots for lead generation (with real metrics) was originally published in Chatbots Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
A Chatbot Software… And An Online Money Magnet
Conversiobot is a chatbot software that can let you earn good money.

Do you have an online business?… Or maybe, you wish to start a one?… If it’s the case, this blog post is for you.
Conversiobot. It’s an AI-based chatbot software that can make your life easier and happier. It’s not typical software, it’s a money-making machine (Keep reading to know more about this).
And even a newbie can get started right away. No special skills or knowledge are required… You don’t need to know a thing about coding to start creating chatbots.
So let’s dive into the important part: Who is it for? And how can you benefit from it?
Who is Conversiobot for?… How can anyone benefit from it?
1. Bloggers
Are you struggling to get your visitors to engage with your content?… What if you might take advantage of an Artificial Intelligence Technology to engage with your Visitors instantly?
Conversiobot is something that makes your content incredibly interactive. And helps to automatically convert your visitors into Leads & Sales.
You can start with ConversioBot right now, by copying-pasting a line of “Automated Bot Code” to your Blog.
>> Watch this short video to find out how <<
Pause!…
Do you want to learn about some strategies to Generate FREE Traffic to your Blog or Website?… If YES, grab your FREE copy of the “5 Ways to Generate Free Traffic” eBook, here.
2. eCommerce website owners
So many eComm Marketers struggle to convert their Visitors into Leads & Sales. If it’s the case for you, Conversiobot is what you need.
It’s the best solution to engage with your visitors instantly and convert them into Leads & Sales. And you will avoid spending THOUSANDS of dollars on Live Chat Agents. And without hiring expensive coders.
In fact, all you need to do to activate this “AI” Website Tech is to copy & paste a single line of “Website Code”.
>> You can access Conversiobot here <<
Trending Bot Articles:
1. How Conversational AI can Automate Customer Service
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
3. Chatbots As Medical Assistants In COVID-19 Pandemic
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
3. People who want to build an Email list
Building an email list from your Website is getting harder with each passing year. Your Website visitors have probably seen squeeze pages and opt-in forms a million times across the Web. And here is where Conversiobot comes in.

It’s incredible Software for list-building. ConversioBot is an automated Chatbot that engages with your visitors in a really fun and interactive way. It uses sophisticated “Artificial Intelligence” to persuade them to opt-in to your list.
ConversioBot comes with a range of “DONE-FOR-YOU” Chatbots designed to build your list. It’s also fully integrated with major Email marketing services like Aweber, Getresponse, Mailchimp, and Sendlane.
>> You can access Conversiobot here <<
4. Freelancers
Conversiobot is useful for freelancers too. If you’re a freelancer and you struggle to convert your Website Visitors into Clients, this amazing software is all you need.
You could use a Live Chat app on your Website and hire Chat Agents. But only if you’ve got deep pockets and you’re happy to fork out THOUSANDS of dollars for the quality you need. But what if you could save your money? What if you could engage with your visitors instantly, and automatically convert them into Clients? All you need to do to activate this game-changer software is to copy & paste a single line of “Website Code”.
>> take action and access Conversiobot here <<
5. Affiliate marketers
Are you struggling to generate Affiliate Sales? Don’t have a Website? Maybe you do your Affiliate Marketing entirely through Social Media or Videos?
>> Find out how to explode your followers or Subscribers <<

6. Anyone who wants to make money online
How can you make money from Chatbots? Well, most businesses can’t afford to develop their own Chatbots. It’s highly sophisticated technology and it can cost THOUSANDS of dollars to Develop. So they’re looking for a ready-made solution.
ConversioBot is the Internet’s #1 Chatbot for Business Website Owners. It comes with a FULL Commercial License allowing you to sell Bots to hungry businesses. Their highly experienced team will show you exactly where there’s HOT demand for Chatbots.
You can sell their Done-For-You Bots directly to businesses. Think about how many businesses out there have a Website and DON’T have a Chatbot. It’s very common to sell them for $200 to $500 each! Sometimes even more!
They’ll also give you “pitch templates” you can copy and paste. These will do the selling for you. They pitch the benefits of Chatbots as an idea to the business you’re selling them to. So you DON’T need any special skills or experience to build Bots, and you don’t need any selling skills.
>> Watch this short presentation to find out more <<
Plans, Pricing & Money-back Guarantee
Conversiobot offers two plans: Conversiobot LITE and Conversiobot PRO. The PRO version includes some additional features, compared to the LITE one. Some of these PRO features are Unlimited Chatbots, Multi-Site License (which means you can install chatbots on unlimited websites), and FULL Commercial License (You can sell the bots).
The LITE version is for 27$, while the PRO version is for 37$. And it’s a ONE-TIME payment!
You get a full 30 days to put this to the test and make sure this is for you. If for any reason you’re not 100% satisfied, you’ll get a full refund.
If you enjoyed reading this story, then you might find the related below stories worth your time.
- How To Start An Online Business — An Option Explained
- Chatbots to Increase your Conversions and Sales
Disclosure: I will earn an affiliate commission for purchases made through links in this post, with no additional cost to you. Thank you!
Don’t forget to give us your 👏 !




More Than A Chatbot — A Money-making Machine was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.

Here is a quick and easy guide about how you can connect and pair your Google home with Bluetooth speaker. Step 1. Open the Google Home…
Today we’ll be talking about how to make an AI-powered chatbot using Rasa and Python. It doesn’t matter if you have deep knowledge of python or are just a beginner in the world of coding!
Software to be installed:
This article mainly focuses on the AI framework, Rasa, and a little bit of python. Before getting started, let me tell you the required software to be installed for the project.
- Visual Studio 2019 C++ Build Tools
- Anaconda (Conda Package)
I am assuming that you already have Python 3.8 installed in your PC since Python 3.9 version doesn’t work with rasa, it has some issue so I’ll suggest you download version 3.8 if you don’t have it. Here’s the link: https://www.python.org/downloads/. Thank me later :P
You can download the following two softwares from the link provided below (if you don’t already have them on your PC, or you can continue with the article if you do).
Anaconda installation: https://docs.anaconda.com/anaconda/install/windows/
Visual Studio C++ Build Tools: https://visualstudio.microsoft.com/downloads/
A small piece of advice: While downloading Visual Studio C++ Build Tools, go to the download menu and then scroll to the All Downloads section.
From there you’ll find the Tools for Visual Studio 2019, click on the tab
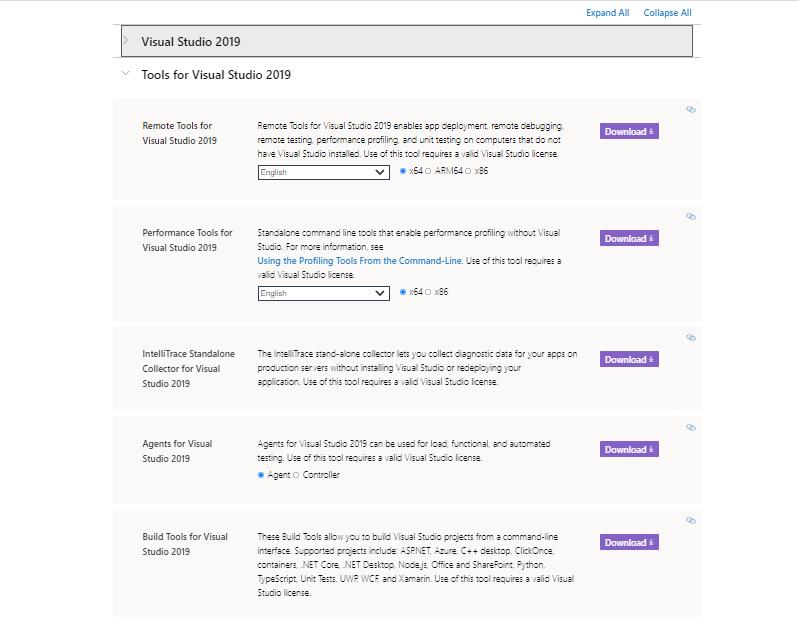
And there it is! You have to download the last one, Build Tools for Visual Studio 2019. Easy-peasy.
If you are still facing some issue downloading the required tools you can follow up on this video to get it done right:
Rasa Installation on Windows | setup RASA on Windows with Demo | RASA — 2: https://www.youtube.com/watch?v=qmMaGicSFCU
Trending Bot Articles:
1. How Conversational AI can Automate Customer Service
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
3. Chatbots As Medical Assistants In COVID-19 Pandemic
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Getting started with the chatbot:
Now that you have installed the required software, you are ready to go!
Create a folder on your desktop named “chatbot”, since we are making a time-zone bot. Although you can name it whatever you want but I’ll go with a simple name.

After opening the folder, click on chatbot, it will show C:\Users\<your username>\OneDrive\Desktop\chatbot, type cmd here and press Enter as shown below.
Now that your command prompt is open, type in the following code to install rasa framework:
pip install rasa
and press Enter, it’ll take a while to install rasa on your PC. After the framework is installed, type in
rasa init
if the above code shows error saying ‘rasa’ is not recognized as an internal or external command, operable program or batch file. Type this
py -m rasa init
Now that the framework is up and running, the Command Prompt will ask you to specify a directory, just tap Enter since you have directly opened the Command Prompt using the directory on which you want to build your chatbot, so you don’t need any specification. It will be created as a default at the same location. Let’s check if you are going by the steps uptil now.
Just like in the above gif, type y for yes, when the bot says Do you want to train an initial model?
It will automatically start training the initial model. Now you just have to wait for the bot to train itself. After sometime, the bot will be loaded and display a green message reading: Bot loaded. Type a message and press enter (use ‘/stop’ to exit):
From here on you can talk to the bot, below is a gif showing a conversation with the bot, you can stop the conversation by typing /stop. It will abort the chat immediately.
You can type a “hi” and “I’m good” to check if the mood bot is working fine or not. The bot you are talking to right now is called a mood bot, it greets and checks your mood, if the reply is good and positive it says “bye” (pretty blunt, huh) and if it’s sad, it shares a picture and says “here’s an image to lighten your mood” or something like that and shares a url of an image.
Well, not getting into the intricacies of how a mood bot should understand one’s emotions, all I want to tell you here is that now you have trained your basic rasa mood bot. From here on you have to go to your file again, if you open your chatbot again you’ll find files names “nlu”, “stories”, “domain” etc stored. Open them in your Visual Studio Code. From here on you can make changes to these files as per your requirement and run the bot again using the code
py -m rasa train
After every change you make in your file’s code, try running this code, and with time you’ll understand that the bot is able to answer different questions as per your code adjustment. Make sure to always update your domain file as and when you update your other files. It is like a mother of all the other files.
What about the code, pal? Yeah the code. I’m sharing that too. Don’t worry. I’m not leaving you all astray.
Here’s the link to all the source codes used. This is my GitHub repository, from here on you can easily download all the codes and paste them in your Visual Studio Code as per the requirement. Since, this is a basic chatbot creation code, I suggest you try adding some more features and make your own unique bots!
GitHub Repository for Chatbot Source Code:
I’m sharing my LinkedIn profile and GitHub profile. Hope we can connect there too!
Link to my LinkedIn Profile:
Arya Pandey - Student Fellow - GirlUp DTU | LinkedIn
Link to my GitHub Repository:
Don’t forget to give us your 👏 !
How to build a chatbot using Rasa and Python was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.

With the emergence of chatbots, many workplace roles have changed and in many cases new ones have been born. As sad as it is, but a conversational AI tester is not one of them (yet). Of course there can be several reasons behind this:
- Lack of resources (human, financial)
- Lack of expertise (knowledge in Test Automation)
- The general belief that Testing only comes in the picture after deployment (wrong)
- Management does not recognize the importance of QA
Therefore, Testing remains still in the background, as the “necessary evil”, which consumes resources and money.
It almost does not matter what technical or role background we had, Chatbot Testing will force us to leave our comfort zone, build up extra knowledge and to learn new expressions and methods.
We, at Botium, have decided to make things easier for companies that have already recognized the huge benefit of Testing Conversational AI, but have not yet had the opportunity to appoint a person for this task, or to gather the required expertise.
Although we believe that using Botium is already as easy as possible, (as there is no need to use Selenium or Appium), we have tried to facilitate the initial steps with maximum automation. Our new Go, Botium, Go feature gives you a huge advantage until you really have the necessary information to successfully set up your first test set.
A Quickstart, true to its name
The new Quickstart will not only give you simplicity and speed to get you started, but it will also help you to see what Test Types are possible for your chosen Chatbot Technology. Not all Chatbot engines forward the necessary information to run certain tests. For some, NLP testing is not possible as the Chatbot does not disclose the required information to run these tests, whereas in other cases E2E Testing is disabled, because the Botium connection to the user interface (web widget, mobile app or voice-controlled application) is done with dedicated Botium E2E Connectors.
Once connected to your Chatbot, Botium Box will automatically assign which Test Types are possible, tailored to the selected technology. The first steps remained largely the same. To kick things off you must select the Chatbot technology in the usual way and check the connectivity.
Trending Bot Articles:
1. How Conversational AI can Automate Customer Service
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
3. Chatbots As Medical Assistants In COVID-19 Pandemic
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
The biggest difference follows in the third step, where Botium Box automatically offers the Test Types that can be performed.
NLP and Regression Testing will be checked and run by default, unless you intentionally skip it. These Test Types are the starting points for testing Conversational AI. When a Chatbot performs well in those disciplines, you do the next step and add Performance Testing, End-to-End Testing, Security Testing and Monitoring.
The executable Test Types are shown in color, and those that are not supported by the selected Chatbot Technology are shown in gray. For certain Test Types that require some adjustment, Botium Box initially works with predefined values. These can of course be changed at any time with one click. As an example, we can see Performance Testing here, which can be changed to the desired values using the sliders.

Live Monitoring also works similarly. In case you enable this feature, you must enter the corresponding person’s or team’s email address(es) (who will be notified in case of complications) and the frequency of the live Monitoring to be executed.
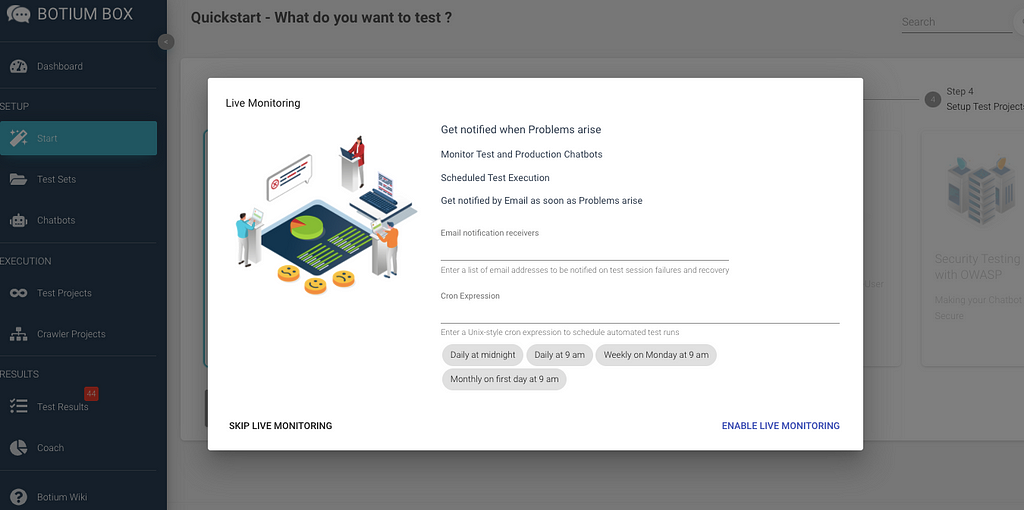
Once you’re done with the settings, you get an overview of everything that Botium will execute for you. In case you are not happy with the results, you can easily go back to the previous page and change the settings accordingly.
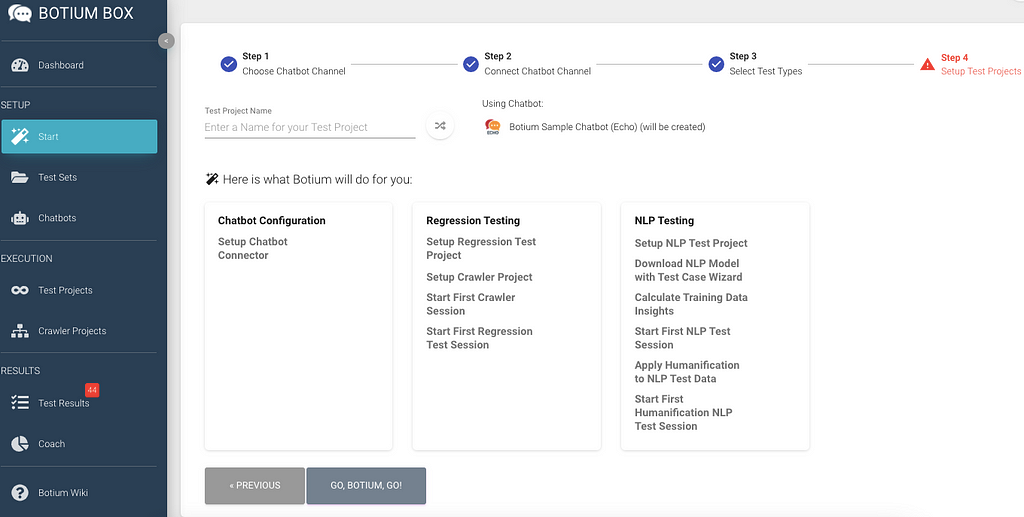
And now, it’s time to make Botium work for you! Press the Go, Botium, Go button, take a sip in your coffee and enjoy the instant results and gratification. The running tests are indicated with a spinning circle and the successfully executed tests are marked with a green checkmark.
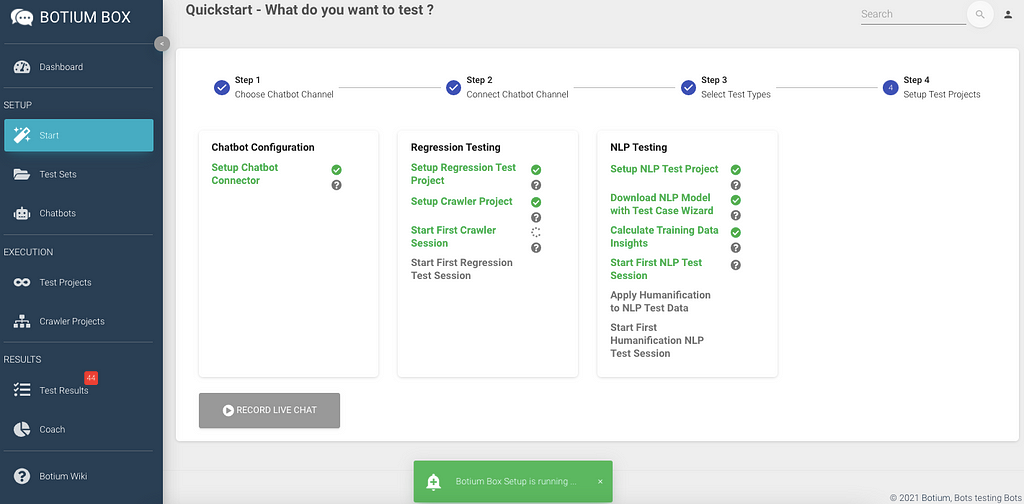
By going on the question marks with your cursor, you get a cool tooltip to the executed test to have some deeper insights. In case you come across some unknown expressions, our Wiki is always there to give you a helping hand!
Congratulations, in 2 mins you’ve set up your first Test Suite and run it successfully!
Conclusion
Our latest feature, Go, Botium, Go simplifies the initial steps of Chatbot Test Automation and allows everyone to get some first insights about their Chatbot efficiency. In 4 easy steps everyone will be capable of running tests and interpreting the results.
Please note that this can not replace continuous testing in an organized form, but it offers a huge advantage in terms of simplifying the start of your Chatbot Test Automation journey. The game changer is no longer the ability, but the willingness!
Don’t forget to give us your 👏 !
How to set up the fundamentals of your Chatbot Testing in 2 minutes was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.

These are the problems that conversational AI face.
Conversational artificial intelligence confronts challenges that expect better progressive technology to endure.
Here, we will catch a glimpse of some of the challenges in conversational AI.
Security and Privacy

At the point when users demand a voice assistant, the information sent must be safely prepared and put away. Voice assistance and chatbots must be paid attention in organizations and the high-security norms that organizations characterize for these channels must be conveyed to their clients to make the vital premise of trust. Particularly while performing sensitive individual data analytics that can be taken, Conversational AI applications must be planned with security in mind to guarantee that protection is regarded and all personal details are kept private or redacted depending on the channel being utilized.
Trending Bot Articles:
1. How Conversational AI can Automate Customer Service
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
3. Chatbots As Medical Assistants In COVID-19 Pandemic
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Conversations in Native Languages

With only a limited section of the world population speaking English, it is a challenge for a voice assistant to converse in a language other than English. As a result, the choice of chatting to a voice assistant in your mother language is critical to winning more people and building faith more skillfully. The languages of varied regions as well as cultural discrepancies are required to be considered.
Discovery and Adoption

Although conversational AI applications are getting progressively simple to use and standardized for everybody, there are still difficulties that can be defeated to expand the number of individuals who are open to using technology for a more extensive variety of use cases. So, instructing your user based on opportunities can enable the technology to be all the more generally welcomed and make a better experience for the individuals who are not friendly with it.
Language Input

Language input can be a difficult area for conversational AI, regardless of whether the input is text or voice. Dialects and background noises can affect the AI’s comprehension of the raw input. Also, slang and unscripted language can create issues with handling the information. Nevertheless, the greatest challenge for conversational AI is the human factor in language input. Feelings and sarcasm make it hard for conversational AI to understand properly and react appropriately.
Simultaneous Conversations
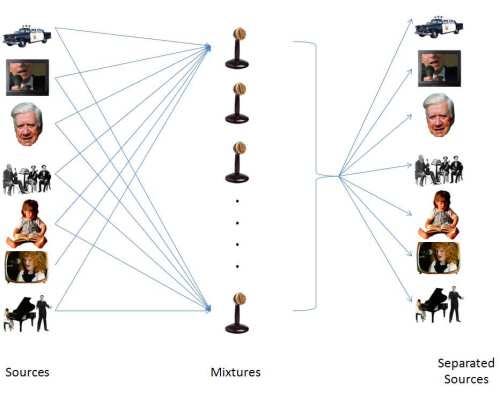
We all know that most of us keep our smart speakers in our living room and most of us use voice assistance in our smartphones. So, in these situations, we can realize that in these places numerous people could probably have a discussion or deliver instructions. In this situation, the voice assistant might get confused. Hence, it requires skill to differentiate identical voices from each other and not distract user accounts, therefore revealing sensitive user information.
Don’t forget to give us your 👏 !
Top Challenges Faced by Conversational AI that You Should be Aware of was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.
 Open-Sources ‘Macaw’, A Versatile, Generative Question-Answering (QA) System") | OpenAI’s GPT-3 system is the best at many tasks, including question answering (QA), but it costs money and can only be used by approved users. While there are other pretrained QA systems out on the market, none has matched its few-shot performance so far. As a possible solution to the above problem, a team of researchers from AI2 has just released Macaw. This versatile and generative question answering system exhibits strong zero-shot performance on a wide range of questions. The best part of Macaw is that it is publicly available for free. 5 Min Quick Read| Paper | Code| AI2 Blog[link] [comments] |
: An End-To-End Attention-Based Model For Action Anticipation In Videos") | Every day, people make countless decisions based on their understanding of their surroundings as a continuous sequence of events. Artificial intelligence systems that can predict people’s future activities are critical for applications ranging from self-driving automobiles to augmented reality. However, anticipating future activities is a difficult issue for AI since it necessitates predicting the multimodal distribution of future activities and modeling the course of previous actions. To address this crucial issue, Facebook AI has recently developed Anticipative Video Transformer (AVT), an end-to-end attention-based model for action anticipation in videos. The new model is based on recent breakthroughs in Transformer architectures, particularly for natural language processing (NLP) and picture modeling. It is more robust at comprehending long-range dependencies than earlier approaches, such as how someone’s previous culinary steps suggest what they will do next. Quick 5 Min Read | FB Blog| Paper| Code| Project [link] [comments] |

")

{kind=link}

Background:
I used a GAN or (generation adversarial network), a 330 BC bust of Alexander the Great by Leochares, and the picture of Alexander’s face by artist Jude Maris to create a lifelike portrait of Alexander the Great.



A generative adversarial network (GAN) is a machine learning framework designed by Ian Goodfellow. The concept was originally published in the 2014 paper titled “Generative Adversarial Networks”. The core idea is to create a system where 2 neural networks compete with each other in a game that generates new data with the same statistics as the training set. For example, a GAN trained on photographs can generate new photographs that look at least superficially authentic to human observers.

I decided to use the image of the Head of Alexander, found near the Erechtheion of the Athens Acropolis in 1886 as the base image. It is thought to be an original work of the sculptor Leochares, made around 330 BC. Starting with this image made sense to me since it is the earliest and the cleanest depiction of Alexander I could get my hands on.

As for style, I used the interpretation of Alexander’s face by artist Jude Maris. Jude Maris used the Marble head of Alexander at the Istanbul Archaeological Museum as the base image.
The colour and other details were digitally added by the artist according to the artist’s interpretation of information available on Alexander’s appearance. (e.g. Heterochromia, blonde hair, sunburnt Greek/Masodanian complexion etc)
But since the image is based on a bust originally made a long time after Alexander's death, I thought it would be worth it to use a more “contemporary” bust of Alexander to get a more accurate reproduction of the shape of his face.
Caveat: I think this is probably what Alexander looked like on his best days because I do not imagine sculptors would be inclined to depict Alexander the great on one of his bad days — which I am sure the great conqueror wasn’t immune to.
Sources:
👉Alexander the great’s appearance, character, personal life, eating and partying habits
👉Ganbreeder on GitHub
I used GAN and a 330 BC sculpture to find out what Alexander the Great looked like was originally published in Archie.AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Whale Science 🐋
I did a quick estimation to figure out what kind of investment you’d need to be able to move the Bitcoin market in the short term, in a particular direction.
I looked at Gdax trading data which handled about 2.98% of all BTC trading volume on February 26th, 2018.
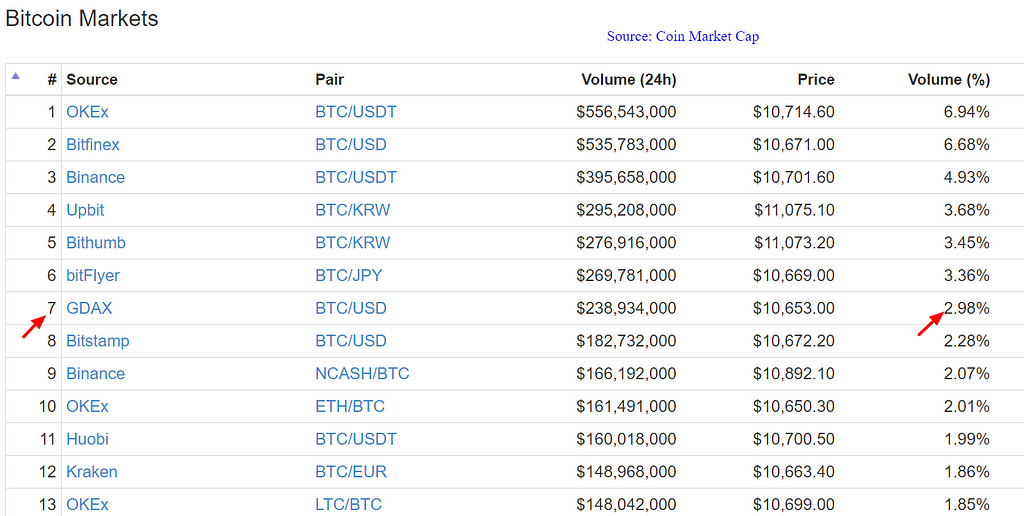
On February 26, between 11: 54 PM PST and 11:55 PM PST, the total volume traded on Gdax was 65 Bitcoins which was worth around $686,440 USD at the time. This resulted in a .557% increase in the price of Bitcoin.
I picked this particular minute for my example because it had visibly higher trading volume compared to the minutes before it.(See image below).
We can now estimate that the total volume of Bitcoins traded in ALL markets during that 1-minute was about 2181 Bitcoins (~23 million USD worth) from the fact 65 Bitcoins traded on Gdax represented 2.98% of all Bitcoin trade volume in the world.
The actual total volume should be lower since it is unlikely that all markets are completely efficient and received the same magnitude of above average volume like Gdax did during that 1-minute in question — But we will continue with this estimation for simplicity.
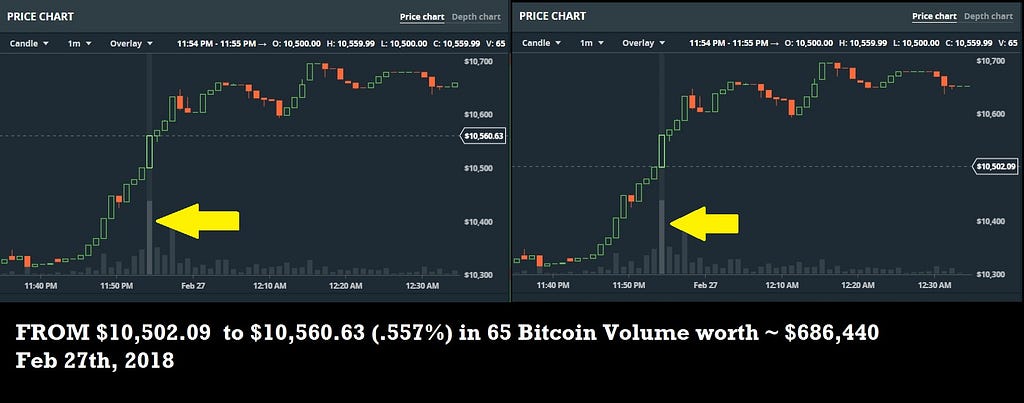
This means that during that 1-minute, $23 million USD worth of bullish trades increased total market value of Bitcoin by over $1 billion USD (.557% of $180.77 billion total value of all Bitcoins)
Crudely put — It is possible for someone with access to $23 million USD to pump the price up by .557% in one minute.
What About Ethereum?
I did the same calculation for Ethereum for that exact same minute — between 11: 54 PM PST and 11:55 PM PST on February 26th, 2018.
Total volume traded on Gdax during that one minute was 120 ETH and resulted in a .41% increase in the price of Ethereum.
Gdax represented 2.97% of all ETH trades which puts the total estimated trade volume during that minute at 4040 ETH which was worth around $3.57 million USD at the time.
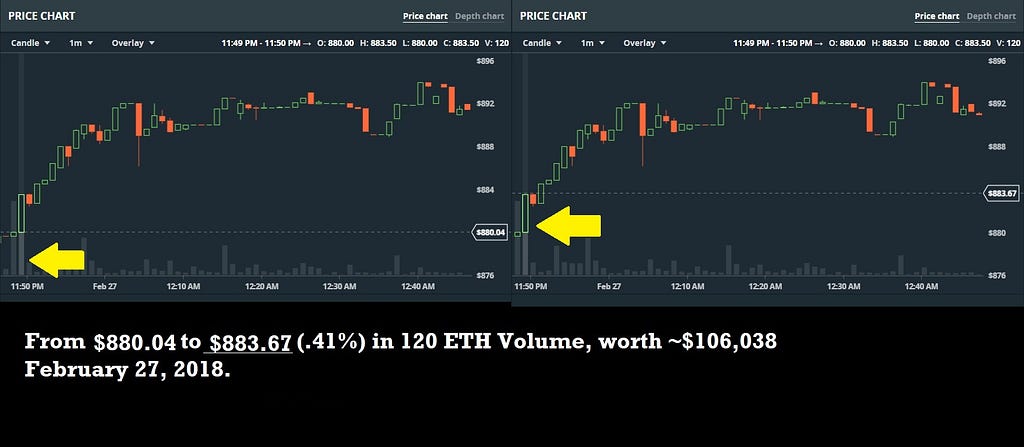
Therefore, we can estimate that a $3.57 million USD worth of bullish trades in Ethereum resulted in an increase of $363 million to the total market value of all ETH(.42% of $86.44 billion USD, total market value of Ethereum)
WHAT DOES IT ALL MEAN?
- A lot more extensive analysis is required before any conclusion can be drawn from this. In future, I’d like to look at different time cycles besides one minute and include a lot more data than just the one minute I picked on a random day to do my calculations. However, this simplified calculation does give us some idea about the sensitivity of the market.
- It would also be interesting to look at how this “whale-effect” has changed over time.
- I assume it was much cheaper to move the market when Bitcoin had a substantially smaller number of hodlers. I also do not doubt that it will get progressively more and more expensive to be able to move price.
- This may sound counter-intuitive but Bitcoin needs a lot more whales and deep pockets. It is relatively easier and cheaper for a whale to influence the market if there are not enough other big players. But with a lot of whales in the market, a single whale no longer has the same influence. For reference: There are 2,043 billionaires worldwide (Forbes) and 35 million millionaires worldwide (Credit Suisse)
- This is not meant to be a financial advice. Please invest responsibly.
Note:
- Glad you stopped by. When I’m not staring at crypto prices, I am usually working on my AI/ML startup Archie.AI — The Artificially Intelligent Data Scientist. Do check it out if you’re interested in that sort of thing.
How Much Money Do You Need to Move the Bitcoin Market? was originally published in Archie.AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
It’s about connecting with the fans, not creeping them out

To me, small, personal projects are always opportunities. Opportunities to learn, to be creative, and to be heard.
During the past five years, I’ve run and managed nearly a dozen web projects, with traffic ranging from tens to tens of thousands visitors each day. Naturally, larger websites have more at stake. They demand round-the-clock monitoring and weekly analysis. But analytics play a huge role in small, personal projects, too.
With less-frequently visited properties it’s a lot harder to derive statistically-significant conclusions. Data is noisy and takes a long time to collect. Acting on that data is also difficult. But this knowledge is valuable for understanding the people who take the time to watch, read, and react to your creative expressions.
A few years ago I was very much into making music. I performed live and distributed records online. Being an introvert I eventually gravitated towards hiding with my guitar in the bedroom and creating sounds in private. Still, I loved being on the stage, as there is no better way to be with people who happen to like you and/or your work.
Never the less, my public appearances have receded over time. Most of my creative work is now online (as a film photography publication and a community blogging platform). The people who happen to like it and consume regularly only manifest themselves as tiny spikes on the traffic curve reported by Google Analytics. Knowing this little about the audience creates a significant interaction void.
As there wasn’t much that I could do with my analytics I switched to Archie Email Reporting product for casual weekly digests. Interestingly, a few months in I began to understand my audience a little better, or, at least, it felt like I did. I knew whether my work is getting more or less popular, where the visitors came from, whether the people are interacting with my content, and what pages, according to the bot, deserve my attention. All without having to obsess about the data via analytics dashboard.
My resulting understanding of the audience isn’t very scientific. But a rough overview of the crowd does draw a decent picture on seasonal and hourly popularity (like the busy months, or, what time of the day do people visit my site most often). Going beyond this kind of knowledge requires more traffic to come up with statistically significant answers. But the real advantage of being small is to be able to talk to people on a personal level and spend less time data mining (while still keeping track).
Large businesses are spending a lot of money on advanced intelligence, which today is backfiring with harsher compliance requirements (like GDPR) and overall public mistrust. At the same time, small ventures have an advantage in the ability to use analytics reports as a rough gauge of performance and to focus on interacting with fans and customers, something we can do without having to scale.
On Twitter, I regularly engage in conversations, many of which are taken as invaluable feedback or messages of support. I spend my time at the places of gathering for the likeminded individuals, like film development labs and exhibition galleries. All of which have a much greater impact on the success of my small venture, defined by the size of the audience and their ability to appreciate my efforts.
To get to this balance between guestimation and science, automation and personal approach I had to try a lot of different techniques. In the end, for any website that receives less than 5K unique visitors per month this method is perhaps the best. No excessive tracking or obsessive analysis. Instead, a healthy presence online (outside of the publishing platform) and a strong reliance on physical/real-world connections.
With the casual data approach, I get to have meaningful, guided interactions with the community without having to spend time serving and dissecting non-existent crowds.
Originally published at www.archie.ai.
Why Data is Important for Small, Personal Web Projects was originally published in Archie.AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
A Better Naming and File Organization System

The curse and the gift of React.js is the fact that it is not opinionated in terms of how you structure your components and files. Do what you want and it’ll work. But with every new project it’s a “blank slate” problem.
This article is written from a perspective of a person building (and finally refactoring) the front-end of a blogging platform designed for film photography enthusiasts. Besides listing and displaying articles, the app provides admin controls and a full rich text editorial suite, comprised of 280 files and folders. The app in question is Analog.Cafe.
Preface 1: “dumb” and “smart” components: not a good way to sort your files.
- app/
- components/
- containers/
When I began working on my application, coming from an intensive year with Ruby on Rails builds for Archie.AI (a fairly opinionated framework) I’ve hit the wall trying to figure out how to structure and name the numerous files with React. The most common advice at the time was to segregate the components into pure functions and stateful components.
The expectation with this method is that your components will inevitably get reused elsewhere. Although this may be true for many projects, I can’t see how it could be the case for all applications. Furthermore, ripping the functionality apart and placing the pieces of a component that performs the same function into separate corners of your filesystem is counter-productive and counter-intuitive.
With some experementation I’ve come up with a better system (below).
Preface 2: styled-components, they aren’t CSS; they are components.
styled-components is my library of choice when it comes to baking CSS into React projects. It’s very good.
A common pattern of usage with it is to separate styles into styles.js, a reminiscent of the file structure we used to have with simpler hand-written HTML files not too long ago.
Turns out this is not a practically good idea. Namely, because this method creates a third type of component (in addition to above-mentioned smart and dumb). What’s worse, this type of component has a completely separate organizational method, which attempts to mimic conflicting paradigms.
I recommend treating styled-components just as what they are — React components.
The Interface Pattern.
The Interface Pattern is a reminder that we are building a front-end application, which is easier to understand and structure when it’s thought of as a compilation of visual interface elements. This pattern consists of suggestions on file and folder structure, preferred export types, commenting practices, and file size recommendations.
File and folder structure shape.
- app/
- core/
- admin/
- user/
- constants.js
- index.js
- store.js
- utils.js
Note: you can browse the entire application structure for Analog.Cafe in this repo.
My application is divided into three major sections: core/ admin/ and user/. In your case, you may not have any sections if the app isn’t big enough. Then you can structure your app/ folder just like the contents of the above sections (see below).
The four JavaScript files above should be self-explanatory, but with a few caveats. In this example they serve as index files, where they store only the most basic and commonly-used exports: index.js contains the main wrapper React component for the app, store.js combines the reducers found inside the above three application sections and exports a Redux store, while utils.js and constants.js contain the most common JavaScripit function snippets and reusable constants.
- core/
- components/
- constants/
- store/
- utils/
Inside each of the application sections are four folders which resemble the shape of the app/ directory. The only difference is that this shape forces you to create more files in your utils/and constants/folders which is better for the organization and should make tree-shaking work better too.
If you are not splitting your app into sections the above folders could be placed inside your app/ folder, instead of core/.
- constants/
- messages-.js
- messages-article.js
- routes-article.js
- rules-submission.js
- utils/
- actions-session.js
- messages-profile.js
Both constants/and utils/ folders have similar file-naming patterns. The first keyword is either messages, routes, rules, or actions. Followed by a dash and a keyword describing a specific part of your application view. I understand that this is not the most foolproof naming convention, however, you may be able to understand it much better in practice. The main objectives should be consistency and clarity.
Note the file named messages-.js which contains strings and objects designated as user-facing messages, not assigned to any specific part of the application view.
- store/
- actions-article.js
- actions-submission.js
- reducers-article.js
- reducers-submission.js
The store/ folder is for Redux. It contains pairs of files (actions- and reducers-) for each part of your application view. Simple; all in one place.
- components/
- controls/
- icons/
- pages/
- routes/
- forms/
- vignettes/
components/ folder: I found the above six types of components to be fairly inclusive way to organize an application. It’s required to have such sub-folders to quickly find what you are looking for and understand application structure. Otherwise you may be stuck with hundreds of folders in this part of your app. This is how I distinguish them:
controls/ — Buttons & button arrays, modal boxes, links, nav bars, menus, etc.
icons/ — Graphic elements made with React and meant to stay as part of an app, such as integral SVGs or CSSs.
pages/ — Components that are meant to take over a whole or a meaningful part of a screen space.
routes/ — This folder is specifically for React Router route components.
forms/ — Input elements.
vignettes/ — Smaller components that do not belong anywhere else.
- controls/
- Card/
- index.js
- components/
- CardFigure.js
- CardHeader.js
Each of the component folders would have names written in CamelCase, with an optional index.js at their root, which would tie everything together. If necessary, components/ folder could be placed inside, which can contain styled-components or React.js components which would directly help compose the main component (in this case, Card/ component).
Note 1: There is no distinction or rule here between “smart” and “dumb” components, but the “smart” components naturally tend to end up at the root of the main component in index.js — which you could use to your advantage.
Note 2: There is nothing preventing you importing from files located in other application sections; a lot of the time it’s required and there’s nothing wrong with that. Feel free to require admin/ utils in your core/ components.
Note 3: You may have noticed that sub-components do not have their own folders. That makes for easier readability and better folder structure. They could, of course, be placed in their own folders if they in-turn have their own sub-components, but that would be messy. Try to keep your file tree as flat as possible.
Preferred export types.
A simple rule is to prefer named exports like export const function Name ()=>{} in constants/ utils/ and store/ — this will encourage you to balance the number of files in those folders nicely.
However, all components should strive to export only default exports with some exceptions where they could contain both default and named exports in very small files. This simple rule will force you to create more components (which are by the way a lot easier to name than more rigidly-structured constants and utils files), which in turn will create a number of benefits in terms of the final bundle size and app readability (fewer lines of code per file).
File size recommendations.
No more than 300 lines per file. Anything bigger than that warrants splitting it.
Commenting practices.
I used to think that more comments in the code is better. Until I learned otherwise. Plentiful comments could be useful when creating a tutorial, however, they tend to pollute application files and encourage bad variable naming practices. So if the code feels difficult to understand, it should be reviewed and corrected for a more comprehensible namings and style. Use tools like Prettier to your advantage.
Write readable code instead of something that you needs a manual.
It may seem like there’s a lot to deal with, but in practice, it could be easily achieved and understood by the whole team. Have a look at the repo that already uses this method to get yourself acquainted. Refer back to this text to get the details and the reasoning behind each choice.
As you may have noticed I haven’t mentioned anything about where to place tests. This method also hasn’t been tried in a great diversity of production systems so there may be some things I missed or got wrong. In those cases, you may have to adapt, and if you got time please let me know so that I could make this guide better.
🍻
Originally published at www.archie.ai.
Structuring React.js Web Applications was originally published in Archie.AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Please, feed your data to the machines.
Artificial intelligence is taking the demand for data to a new level. 📈
Let’s say you have access to 5,000 X-ray images of patients who were correctly diagnosed with a particular type of cancer — Type A.
Today, it is surprisingly easy to use this data to train a bot to detect this cancer in new patients.
To build this bot, you’d build an image classifier powered by a neural net and the 5,000 X-ray images would be your training data set.
You’d add another 5,000 X-rays of patients without cancer so the classifier has examples of both healthy and affected X-rays.
In essence, this image classifier bot would look for common patterns at pixel level using image gradients and correlate that pattern to Type-A cancer using a widely used machine learning algorithm called back-propagation.
Note that YOU don’t have to specify the patterns at the pixel level to the bot for it to detect the cancer. That would be a highly inefficient process and possibly inaccurate as well.
Instead, in our deep learning model, the bot looks for the patterns itself. It painstakingly evaluates small grids of pixels of an image with the cancer and compares it to the corresponding grid in ALL the other images to find the patterns that exist. For further reading, you can check out concepts like kernel convolutions or how bots are detecting various object in Kaggle competitions.
If you want to dive deeper into the tech, you can read my essay “Learning at Scale & The End of ‘If-Then’ Logic”.
The point is, using currently available open-source/SaaS deep learning platforms, a bit of motivation and access to the right data set, one could set this bot up in no time.
Once trained, if you input a new patient’s X-ray, the classifier would be able to say things like “There’s a 98% chance that this is a Type A Cancer”.
If you’ve been through a cancer diagnosis process of a loved one, you know how important it is to be certain. That’s why people get the second, the third and the fourth opinion from different doctors.
Using this bot, every patient can be more confident about a diagnosis, a lot faster.
The best part is that if you continue to add more X-ray images of correctly diagnosed Type A cancer, the bot will continue to get better at detecting it.
As machine learning techniques become more mainstream, a lot more value will be placed on data because machines can learn from it to do our jobs better than us.
This above use-case isn’t science fiction.
At John Radcliffe Hospital, a team of researchers from Oxford University are using electrocardiogram images (Eco test) of the heart to detect heart diseases. The system is called Ultromics and it consistently performs better than human cardiologists. The team has access to Oxford University’s heart imaging database and they are training their machine learning algorithms with these images to detect various heart diseases.
Google’s DeepMind is using a similar system to train an AI to detect eye disease by looking at thousands of retina scans at London’s Moorfields Eye Hospital.
In a double blind study, IBM Watson for Oncology’s breast cancer treatment recommendations was 90% concordance with the recommendation of a tumor board consisting of multi-disciplinary doctors and practitioners. Here, the training data comes from medical records of past patients, medical journal and books.
Needless to say, AI/ML use-cases are not limited to healthcare but they show us how valuable data is to solve real problems.
Most organizations/businesses/governments are sitting on top of literal goldmines of data that could be made into powerful AI products.
Unfortunately, not enough is being done. Not fast enough.
Data is a source of great power. And with great power comes great responsibility.*
So if you’ve got access to valuable data, you better be building something useful with it.
Note:
🤖If you’re interested in learning more about my work with AI/ML, check out my startup Archie.AI- The Artificially Intelligent Data Scientist.
🤖If you’re interested in building machine learning models, check out our workshops on YouTube.
🤖Want me to help you build your AI/ML project? Email me: i@eurekaking.com
Additional recommended essays on machine learning/artificial intelligence from team Archie.AI
👉A Dozen Times Artificial Intelligence Startled The World.
👉The Power of Natural Language Processing.
👉Artificially Intelligent Engineers — How AI Will Kill All Engineering Jobs. And Why It Is a Good Thing.
*Spiderman, David Lapham
Stop Sitting On All That Data & Do Something With It ⚙️ was originally published in Archie.AI on Medium, where people are continuing the conversation by highlighting and responding to this story.